
摘 要: 動態時間規整DTW是語音識別中的一種經典算法。對此算法提出了一種改進的端點檢測算法,特征提取采用了Mel頻率倒譜系數MFCC,并采用計算量相對較小的改進的動態時間規整算法實現語音參數模板匹配,能夠實現孤立詞、特定人、小詞匯量的語音識別,并用Matlab進行了算法仿真。試驗結果表明,改進后的算法能夠有效地提高系統對語音的識別率。
關鍵詞: 語音識別;端點檢測;Mel倒譜參數;動態時間規整
在孤立詞語音識別中,最為簡單有效的方法是采用動態時間規整DTW(Dynamic Time Warping)算法,該算法基于動態規劃(DP)的思想,解決了發音長短不一的模板匹配問題,是語音識別中出現較早、較為經典的一種算法。DTW是把時間規整和距離測度計算結合起來的一種非線性規整技術,算法較為簡潔,正確率也較高,在語音識別系統中有較廣泛的應用。
本文對DTW算法提出了一種改進的端點檢測算法,對提高系統的識別率有很好的實用價值[1]。
1 語音識別系統與DTW算法原理
本質上講,語音識別就是語音信號模式識別[2],它由訓練和識別兩個過程完成。訓練過程是從某一說話人大量語音信號中提取出該說話人的語音特征,并形成參考模式。識別過程是從待識語音中提取特征形成待識模式,與參考模式進行模式匹配、比較和判決,從而得出識別結果。本系統的結構如圖1所示。

假設測試和參考模板分別用T和R表示,它們之間的相似度用其之間的距離D[T,R]來度量,距離越小相似度越高[3]。為了計算這一失真距離,要從T、R中各個對應幀之間的距離算起。設n、m分別是T、R中任意選擇的幀號,d[T(n),R(m)]表示這兩幀特征矢量之間的距離(在DTW算法中通常采用歐式距離)。
如圖2所示,橫軸上標出的是測試模板T的各個幀號n=1~N,縱軸上是參考模板R的各個幀號m=1~M,N≠M。網格中的每一個交叉點(n,m)表示測試模式中某一幀與訓練模式中某一幀的交匯點。DP算法就是尋找一條通過此網格中若干個格點的路徑。路徑不是隨意選擇的,首先任何一種語音的發音快慢都有可能變化,但是其各部分的先后次序不可能改變,因此所選的路徑必定是從左下角出發,在右上角結束。


式中,sgn[ ]是符號函數。
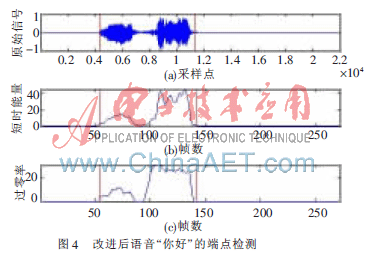
為了提高端點檢測的精度,采用短時能量和過零率進行端點檢測[4]。語音采樣頻率為8 kHz,量化精度為16 bit。數字PCM碼首先經過預加重濾波器H(z)=1-0.95z-1,再進行分幀和加窗處理。在實驗中發現,雙門限端點檢測算法對于兩個漢字和三個漢字的語音命令端點檢測效果不好。以語音“你好”為例,如圖3語音波形圖中,端點檢測只能檢測到第1個字。

如果語音命令中兩個字的間隔過長,使用雙門限端點檢測法會發生只檢測到第一個字的情況,從而可能造成語音匹配錯誤。為避免該錯誤,把可容忍的靜音區間擴大到15幀,如15幀內一直沒有能量和過零率超過最低門限,則認為語音結束;如發現仍然有話音,則把能量和過零率計算在內[5]。
整個語音信號的端點檢測流程設計為四個階段:靜音段、過渡段、語音段和語音結束。在靜音段,如果能量或過零率超越低門限,就開始標記起始點,進入過渡段。在過渡段,由于參數的數值較小,不能確信是否處于語音段,因此只要兩個參數的數值都回落到低門限以下,就將當前狀態恢復到靜音狀態;而如果在過渡段中兩個參數中的任何一個超過了高門限,就可以確信進入語音段。在語音段,如果兩個參數的數值降低到低門限以下,且一直持續15幀,則語音進入停止;如果兩個參數的數值降低到低門限以下,但并沒有持續到15幀,后續又有語音超越過低門限,則認為還沒有結束;如果檢測出的這段語音總長度小于可接受的最小的語音幀數(設為15幀),則認為是一段噪音而放棄。
采用改進后的端點檢測算法,對單個漢字或多個漢字的語音命令均識別正常。圖4為語音“你好”的端點檢測圖。
2.2 語音識別的DTW高效算法
通常,路徑函數Φ(ni)被限制在一個平行四邊形內,平行四邊形的一條邊斜率為2,另一條邊的斜率為1/2。路徑函數的起點為(1,1),終止點為(N,M)。Φ(ni)的斜率為0、1或2。這是一種簡單的路徑限制,如圖5所示。
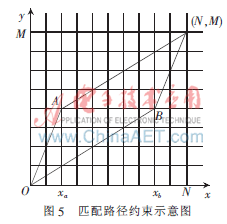
本文的目的是尋找一個路徑函數,在平行四邊形內由點(1,1)到點(N,M)具有最小代價函數。由于對路徑進行了限制,在匹配過程中許多格點實際上是到達不了的,因此,平行四邊形之外的格點對應的幀匹配距離是不需要計算的。另外,也沒有必要保存所有的幀匹配距離矩陣和累積距離矩陣,因為每一列各格點上的匹配計算只用到了前一列的3個網格。利用這兩個特點可以減少計算量和存儲空間的需求。

如果出現Xa>Xb的情況,此時彎折匹配的三段為(1,Xb)、(Xb+1,Xa)和(Xa+1,N)。沿X軸上每前進一幀,雖然所要比較的Y軸上的幀數不同,但彎折特性是一樣的,累積距離的更新都是用下式實現:
D(x,y)=d(x,y)+min[D(x-1,y),D(x-1,y-1),D(x-1,y-2)]
由于X軸上每前進一幀,只需要用到前一列的累積距離,所以只需要兩個列矢量D和d分別保存前一列的累積距離和計算當前列的累積距離,而不用保存整個距離矩陣,這樣可達到減少存儲量和存儲空間的目的。
2.3 試驗結果
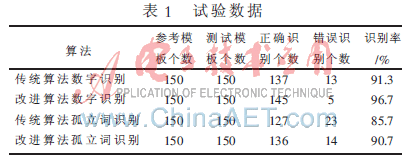
本系統采用改進的端點檢測方法,采用MFCC(Mel Frequene Cepstrum Coeffiients)特征提取和DTW算法來實現語音識別。語音采樣頻率為8 kHz,16 bit量化精度,預加重系數a=0.95,語音每幀為30 ms,240點為一幀,幀移為80,窗函數采用Hamming窗。采集5個女生,10個男生的數據。共分為兩組,第一組是對0~9十個數字的識別,第二組是對孤立詞的識別,試驗數據如表1所示。
本文研究了語音識別DTW算法和理論,在應用中對雙門限端點檢測算法作了延長可容忍靜音的改進,在說話語音識別算法上對DTW進行了改進和設計,實驗結果表明,該算法可以有效地提高系統的識別率。
參考文獻
[1] 何強,何英.MATLAB 擴展編程 [M].北京:清華大學出 版社,2002.
[2] CHANWOO K, KWANG D S. Robust DTW-based recognition algorithm for hand-held consumer devices[J]. IEEE Transactions on Consumer Electronics, 2005, 51(2):699-709.
[3] MIZUHARA Y, HAYASHI A, SUEMATSU N. Embedding of time series data by using dynamic time warping distances[J]. Systems and Computers in Japan, 2006, 37(3):1-9.
[4] BDULLA A, CHOW W H, SIN D, G. Cross-words reference template for DTW-based speech recognition systems[C]. Conference on Convergent Technologies for the Asia-Pacific Region,TENCON, 2003, 2003:1576-1579.
[5] 劉金偉,黃樟欽,侯義斌.基于片上系統的孤立詞語音識別算法設計[J]計算機工程,2007,33(13):25-27.