
摘 要: 在分析ARQL" title="SPARQL">SPARQL標準和基于Jena的開源SPARQL工具ARQ查詢引擎源碼的基礎上,提出了可支持關聯查詢的擴展SPARQL標準及其設計和實現方案,認真分析了已有的試驗成果。
關鍵詞: SPARQL;ARQ;Jena;RDF;關系路徑;關系查詢
資源描述框架RDF(Resource Description Framework)[1]是W3C組織基于可擴展標記語言(XML)開發的一種元數據描述框架。RDF能夠定義概念以及概念間的關系,描述易被機器理解的信息和知識。它提供的語義模型可用于描述Web上的任意資源及其類型,為網上資源描述提供了一種通用表示框架,解決語義異構問題,實現數據集成的元數據解決方案。同時,RDF可用于數據發現,為搜索引擎提供更強大的搜索功能。RDF通過基于XML語法明確定義的結構化約定來建立語義協定與語法編碼之間的橋梁,以此促進元數據的互操作能力。因此,RDF是解決計算機知識表示問題的最佳選擇,可以很好地描述元數據。
SPARQL(Simple Protocol and RDF Query Language)是為RDF開發的一種查詢語言和數據獲取協議,雖然它是為W3C開發的RDF數據模型定義,但是可以用于查詢任何可以用RDF來表示的信息資源。現行SPARQL能夠滿足類似SQL中基本模式匹配、分組、連接、合并等查詢形式,并能夠根據用戶定義有效地返回映射結果集,能夠滿足基于RDF數據的基本查詢需求。
RDF數據的精髓在于以半結構化數據形式來存儲知識以及知識間的基本關系,比較遺憾的是,目前的SPARQL標準及工具還沒有提供一種有效的途徑來查詢任意指定的兩節點間可能存在的各種關系路徑以及任意指定節點周圍可能散射的各種關系路徑。為了解決如上問題,本文在原有的SPARQL標準的基礎上引入新關鍵詞來描述關聯查詢語義,并在針對基于Jena[2]的SPARQL開源引擎ARQ基礎上進行實驗、支持擴展新的標準及功能的方案。
1 SPARQL語法及擴展
1.1 SPARQL基本語法
1.1.1 基本術語
被“<>”界定的術語是IRI參考[RFC3987],它們代表IRIs,直接地或相對于一個基本的IRI。IRIs是URIs[RFC3986]的一般化,而且完全與URIs和URLs兼容。SPARQL為IRIs提供兩種縮寫機制:namespace前綴和相關的URIs。查詢術語可能是文字字符串(用雙引號“”或單引號‘’括起來),有一個可選擇的語言標簽或可選擇的數據類型IRI。為方便起見,整數能被直接地寫,且被解釋成datatype的類型文字xsd:integer;十進制數被解釋為xsd:decimal,含有一個指數的數被解釋為xsd:double。類型值xsd:boolean也能被寫為true或false。SPARQL查詢變量有全局范圍,查詢時,同一個名字在各處是相同的變量,變量用“?”指出[3-4]。
1.1.2 三元組模式
三元組模式被寫作為一列主語、謂語和賓語,用簡單的方法來寫一些通用的三元組模式,用{}將其聚集在一起。
1.1.3 圖模式
SPARQL查詢語言是基于圖模式匹配的,最簡單的圖模式是三元組模式,如同一個RDF三元組,但在任何主語、謂語或賓語的位置中可能有變量,如{?Book dc:title?title}。復雜圖模式能由簡單圖模式組合而成,常見的復雜圖模式是基本圖模式、組合圖模式、可選擇圖模式、聯合圖模式、RDF數據集圖模式、值約束條件六種模式中的一種。
1.1.4 值約束
SPARQL中的FILTER關鍵字對綁定變量的值進行約束,從而限制查詢的結果。這些值約束條件是對布爾值進行計算的邏輯表達式,并且可以與邏輯操作符&&和||組合使用。例如,可以用過濾器把返回名稱列表的查詢修改為只返回和指定正則表達式匹配的名稱。
1.1.5 查詢類型
SPARQL支持SELCET、ASK、DESCRIBE和CONSTRUCT四種類型的查詢。典型的SPARQL查詢由SELCET、FROM、WHERE三部分組成。SELCET子句指定查詢應當返回的內容;FROM是一個可選的子句,提供了將要使用的數據集的URI,可以指向一個本地文件,也可以指向Web其他地方的某一個圖的URL;WHERE子句由一組三元模式組成,采用基于Turtle的語法表示。這些三元模式共同構成了所謂的圖形模式。ASK:應用程序可以使用ASK形式來測試查詢模式是否有一個解決方案。如果查詢的圖形模式在數據集中有匹配物,那么ASK將返回“yes”;如果沒有匹配物,則返回“no”。DESCRIBE:返回一個圖形,其中包含和圖形模式匹配的節點的相關信息。例如,DESCRIBE?person WHERE{?person foaf: name“Jon Foobar”}會返回一個圖,其中包括來自JonFoobar的模型的三元模式。CONSTRUCT:用來為每個查詢結果輸出一個圖形模式,這樣就可以直接從查詢結果創建新的RDF圖。
1.2 SPARQL語法擴展
擴展的基本原則是不影響原有SPARQL查詢語法及特性,通過引入適當的查詢關鍵字來描述查找指定節點間的關鍵關系。第一個關鍵詞為SEEK,用來表示路徑查詢類型,其用法類似于SELECT、ASK、DESCRIBE、CONSTRUCT等關鍵字;第二個關鍵詞為START,用來描述關系路徑的起點圖模式;第三個關鍵詞為END,用來表示關系路徑的終點圖模式;第四個關鍵詞為NODE,用來描述關系路徑節點的圖模式,以及與起點圖模式和終點圖模式間的連接方式;第五個關鍵詞為CONSTRAINT,用來描述關系路徑的約束,作用類似于FILTER關鍵詞,主要用來限制關系路徑最短長度、關系路徑最長長度、與起點和終點的關系變量前綴、路徑節點變量前綴等,其中最短路徑為默認值為3,最長路徑長度默認值為6。遵循以上擴展標準的節點間關系路徑查詢語法如下。
SEEK ?node,?power,?link
WHERE {
START{
?s1 <http://jena.test/elements/type> “country”;
?s1 <http://jena.test/elements/name> “A國”.
}
END{
?s2 <http://jena.test/elements/type> “country”.
?s2 <http://jena.test/elements/name> “B國”.
}
NODE{
?s1 ?link ?node.
?node ?link ?s2.
?node<http://jena.test/elements/type>“keypoint”.
?node <http://jena.test/elements/power>?power.
Filter(?power>1)
}
CONSTRAIT{
LinkName(“link”)
NodeName(“node”)
MinDepth(3)
MaxDepth(6)
}
}
當只有START描述的起點而沒有END描述的終點時,則用來查找從該起點出發的符合路徑節點中描述的關系路徑,CONSTRAIT依然用來描述路徑的各種約束信息、含義及用法不變,到此便基本完成了對SPARQL標準及語法的擴展工作。
2 基于ARQ開源引擎的擴展
2.1 創建查詢語法樹
ARQ[5]目前支持標準SPARQL語法樹的生成,在擴展標準之后需要加入新的語法樹創建規則,以識別擴展標準中新加入的關鍵詞,最終建立正確的語法樹結構[6-7]。新規則的引入需要保證在SEEK查詢中至少在WHERE子句中出現START關鍵字來描述關系路徑起點的模式,而NODE關鍵字來描述關系路徑中間各節點的模式,最后用CONSTRAIT關鍵字來限制關系路徑長度等屬性。其中END關鍵字為可選路徑,如果沒有關系終點限制,則只需要達到關系路徑最大深度后停止關系查詢即可。若不能滿足上述基本規則,則查詢語法樹創建失敗,可向客戶端反饋語法錯誤。擴展后的語法樹基本邏輯結構如下所示。另外,查詢語法樹對象只是一個中間形式,主要目的是為了生成查詢代數表達式服務。
(project(?node,?link,power)
(path(
start(
bgp(
triiple(?s1 <http:
//jena.test/elements/type> “country”)
triiple(?s1 <http:
//jena.test/elements/name> “A國”)
)
)
end(
bgp(
triiple(?s2 <http:
//jena.test/elements/type> “country”)
triiple(?s2 <http:
//jena.test/elements/name> “B國”)
)
)
node(
bgp(
triiple(?s1 ?link ?node)
triiple(?node ?link ?s2)
triiple(?node<http:
//jena.test/elements/type> “keypoint”)
triiple(?node <http:
//jena.test/elements/power> ?power)
)
)
))))
2.2 生成查詢代數表達式
ARQ引擎在正確生成查詢語法樹后則通過查詢語法檢查,此時可將語法樹中描述的操作轉換為ARQ引擎中與之對應的算術運算操作或者算術運算操作組合[8]。在ARQ引擎中,每種算術運算操作都有一個與之對應的運算操作類型對象,用來封裝和存儲該運算的基本信息以及與其他運算操作之間的協作關系,以達到最終的查詢目的。
擴展SPARQL標準后,ARQ引擎中并不存在與擴展后的關鍵詞對應的算術運算操作類型,即無法將語法樹正確地轉換為查詢代數表達式。因此,在ARQ引擎中引入新的算術操作對象類型(PathOp),該操作類型需要組合起點運算和終點運算兩個基本模式運算對象(BgpOp)以及自身的路徑探索連接運算。PathOp的基本設計原則是在重用已有運算的基礎上加入必要的運算操作達到路徑探索連接的目的,保證原有引擎設計結構與實現方法。
2.3 查詢優化與運算
成功生成查詢代數表達式后,就可以針對查詢代數表達式進行優化。絕大部分查詢代數運算同樣遵循代數運算中的結合定律與分配定律,進行合理排列組合達到降低時間和空間復雜度的目的。新的查詢運算建立在原有運算基礎之上,可以保持針對原有運算的優化原則。
最后是對運算表達式進行運算,ARQ引擎采用在算術運算部分使用修飾者模式,具體運用了結果流迭代器技術,為新的擴展留下空間,同時也盡量保證運算的時空效率。因此在實現擴展運算的時候只需繼承或封裝上級結果流迭代器,在本迭代器中實現路徑探索連接的運算過程。目前采用向后迭代、向前迭代和雙向迭代三種迭代算法。
(1)向后迭代。首先將起點放入候選隊列,取出候選隊列第一項與數據集中的其他節點進行迭代匹配,若匹配成功并且匹配深度小于最大深度約束,則將本條匹配加入候選隊列;若與終點連接成功,則該匹配為一條匹配路徑并返回。重復上述過程,直到候選隊列為空。
(2)向前迭代的過程與向后迭代完全相同,只是將終點放入候選隊列,然后開始迭代過程。
(3)雙向迭代。讓向前與向后迭代同時進行,每個方向都有一個候選隊列,每次向前隊列匹配成功則與向后候選隊列中的項進行匹配連接,若連接成功,則返回該連接匹配,反之亦然。雙方將各自匹配成功的并且小于最大深度約束的匹配項加到各自的候選隊列,當其中任意一方的候選隊列為空時,迭代結束。
3 實驗結果分析
3.1 節點間關系路徑
節點間關系路徑實驗在測試數據集上進行,查詢條件與圖1基本一致。該實驗主要測試查詢節點間可能存在的關系路徑,選取的起點為“A國”,終點為“B國”,查詢出來的路徑較多,經過power因子過濾和修正之后,主要有3條路徑,圖1給出了這3條關系路徑的基本邏輯關系圖。

3.2 單節點周圍散射關系路徑
單節點周圍散射關系路徑實驗主要測試在不限定終點的情況下查詢單節點周圍散射的各種關系路徑。本實驗僅限制起點“A國”,同樣查出的路徑比較多,經過power因子過濾和修正后主要有8條路徑,圖2給出了這8條路徑的基本邏輯關系圖。
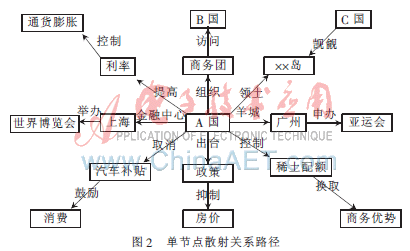
這兩類實驗測試表明,所做擴展基本能達到預期的目標,但同時也存在一定的問題。在比較復雜和寬泛的語義環境下,節點間的關系很多而且比較繁雜,如何從如此多的關系路徑中搜尋到有意義的路徑仍然是一個難題。本實驗嘗試使用一個power因子來描述單個關系的重要性,在一定程度上可以緩解這個問題,但仍然還有較大的不足之處。
本文所要解決的問題是在項目實踐中提出的,目的是為了豐富和完善現有的SPARQL標準及功能,增強RDF數據的實際應用能力,滿足語義網應用與開發中對關系路徑搜索能力的需求。通過閱讀大量的文檔及文獻,提出了比較合理的SPARQL擴展標準,并認真閱讀開源ARQ查詢引擎源碼,在原有功能的基礎上植入新的關系路徑搜索功能,相信會進一步提升SPARQL及RDF的應用前景。下一步的工作計劃是進一步完善和加強SPARQL在關系搜索領域的能力。例如,引入排序因子等技術提升查找路徑的關鍵性與有效性,同時進一步提高SPARQL搜索性能。
參考文獻
[1] Resource Description Framework (RDF)[EB/OL]. http://www.w3.org/2001/sw/wiki/RDF,2011-01-03.
[2] Jena-a semantic Web framework for Java[EB/OL]. http://openjena.org/index.html,2011-01-03.
[3] Sparql2sql a query engine for SPARQL over jena triple stores[EB/OL]. http://jena.sourceforge.net/sparql2sql/,2007-11-10.
[4] SPARQL Query Language for RDF[EB/OL]. http://www.w3.org/TR/rdf-sparql-query/,2008-01-15.
[5] ARQ-SPARQL Processor for Jena[EB/OL]. http://openjena.org/ARQ/,2011-01-03.
[6] Extensions in ARQ[EB/OL]. http://openjena.org/ARQ/extension. html,2011-01-03.
[7] ARQ-Extending Query Execution[EB/OL]. http://openjena.org/ARQ/arq-query-eval.html,2011-01-03.
[8] ARQ-SPARQL Algebra[EB/OL]. http://openjena.org/ARQ/algebra.html,2011-01-03.