
摘 要: 為了從具有海量信息的Internet上自動抽取Web頁面的信息,提出了一種基于樹比較的Web頁面主題信息抽取方法。通過目標頁面與其相似頁面所構建的樹之間的比較,簡化了目標頁面,并在此基礎上生成抽取規則,完成了頁面主題信息的抽取。對國內主要的一些網站頁面進行的抽取檢測表明,該方法可以準確、有效地抽取Web頁面的主題信息。
關鍵詞: 信息抽取;相似頁面;樹比較;抽取規則
隨著Internet的飛速發展,Web已經發展成為一個共享的數據空間,互聯網已成為人們獲取信息的重要渠道。而在Web數據呈幾何級數增長的同時,用戶查找、定位自己所需的信息變得越來越困難,如何快捷、有效地搜索信息成為亟待解決的問題,Web信息抽取技術正是在這種背景下應運而生。Web信息抽取技術的核心是能夠從頁面所包含的無結構或半結構的信息中識別用戶感興趣的數據,使其更為結構化、語義更為清晰的格式。比如從新聞報道中抽取出新聞的時間、地點、主要內容等;從介紹商品的網站上抽取出商品的價格、參數、評價等。通常,被抽取出來的信息以結構化的形式描述,可以直接存入數據庫中,供用戶查詢以及進一步分析利用。當今,Internet已經成為發布和傳播信息的最重要手段,網絡上的信息和活動對人們的影響越來越明顯。一個良好的Web信息抽取系統可以高效地收集所需的網絡信息,并加以分析利用,如應用于專業數據獲取、股票預測、用戶行為愛好分析等。目前,像Newsbot、Shopbot等一些針對特定領域的信息抽取/集成軟件已經投入了商業應用,幫助人們隨時獲得最新的新聞消息或收集同一商品的不同價格信息以決定合理的購買方式。
Web的數據大部分都是以HTML形式出現的,這是一種半結構化的數據,缺乏對數據本身的描述,不含清晰的語義信息,模式也不太明確,這使得應用程序無法直接解析并利用頁面上的信息;并且由于人們審美和商業的需求,充斥著大量與主題無關的修飾信息,如圖片、廣告、各種腳本語言等。如何排除干擾,有效地確定Web頁面中的主要數據區域并從中抽取出大家所關注的主題信息是本文的主要工作。
Web信息抽取技術發展至今,已經有了很多比較成熟的方法,如基于文本統計的信息抽取技術[1]、基于HTML結構的信息抽取技術[2]、基于隱馬爾科夫模型的信息抽取技術[3]等。這些方法各有利弊,但有一個需要共同面對的問題是對于目標頁面的不定期改版,原有的抽取規則可能會失效。本文提出的基于樹比較的Web主題信息抽取技術是一種基于HTML結構的信息抽取方法。通過目標頁面與其相似頁面的比較訓練,簡化目標頁面并生成抽取規則,以此規則來完成目標頁面主題信息的抽取。當頁面改版,抽取規則失效時,會自動進行重新學習而生成新的抽取規則。經驗證,本抽取系統具有良好的健壯性,能很好地解決這個問題。
1 相關概念
1.1 DOM樹
DOM(Document Object Model)是由W3C制定的一種與平臺和語言無關的標準接口規范,它允許程序和腳本動態訪問、修改文檔的內容、結構和類型。它定義了一系列的對象和方法對DOM樹的節點進行各種隨機操作。DOM樹中的節點可分為4種不同的對象:(1)Document對象。作為樹的最高節點,Document對象是對整個文檔進行操作的入口;(2)Element和Attr對象。這些節點對象都是文檔某一部分的映射,節點的定級層次恰好反映了文檔的結構;(3)Text對象。作為Element和Attr對象的子節點,Text對象表達了元素或屬性的文本內容。Text節點不再包含任何子節點;(4)集合索引。DOM提供了幾種集合索引方式,可以對節點按指定方式進行遍歷,索引參數都是從0開始記數的。DOM樹中的所有節點都是從Node對象繼承而來,Node對象定義了一些最基本的屬性和方法,利用這些方法可以實現對樹的遍歷,同時,根據屬性還可以得知節點的名稱、取值并判斷其類型。
1.2 XPath
XPath即為XML路徑語言(XML Path Language),它是一種用來確定XML文檔中某部分位置的語言。XPath基于XML的樹狀結構,提供在數據結構樹中找尋節點的能力。最常見的XPath表達式是路徑表達式(XPath名稱的另一來源)。路徑表達式是從一個XML節點(當前的上下文節點)到另一個節點、或一組節點的書面步驟順序。這些步驟以“/”字符分開,每一步有三個成分:軸描述(用最直接的方式接近目標節點);節點測試(用于篩選節點位置和名稱);節點描述(用于篩選節點的屬性和子節點特征)。本文的抽取規則就是以XPath的形式給出,使用XPath定位所要抽取的信息在DOM樹中的節點。
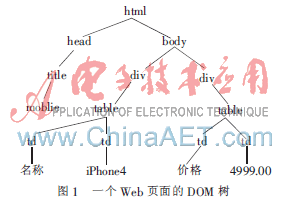
用Xpath來定義抽取規則,雖然簡單明確,但從抽取系統的健壯性來考慮,卻存在著一定的隱患。假設要從圖1這樣一棵DOM樹上抽取商品iPhone4的價格,則可以定義XPath/html/body/div[2]/table/td[2]/text()為抽取規則。但是,當目標頁面的布局稍有改變時,該抽取規則可能就不再適用,而需要重新訓練學習[4]。比如,第一個div被刪除,第二個div的table下新加了一些節點等。本文提出的信息抽取算法在當前的抽取規則失效后,會自動獲取改版后的頁面重新進行再學習、訓練以生成新的抽取規則,確保了信息抽取系統的有效性。
1.3 DSE算法
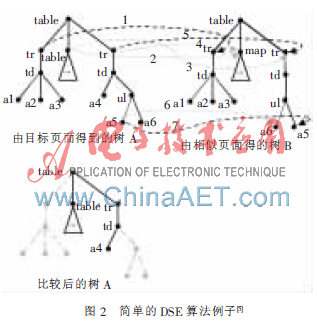
對于Web主題信息抽取來說,很重要的一步就是簡化待抽取的Web頁面,確定主題信息所在的數據區域,刪減與主題無關的干擾信息。DSE[5](Data-rich Section Extraction)算法能很有效地完成這個工作。DSE的提出是基于這樣一個事實:在同一個網站下,往往有大量使用同一設計模板的Web頁面,這些頁面具有相同或相似的HTML結構。同時,廣告、導航信息等與主題無關的內容在這些頁面的相同位置不斷重復出現。這時,通過對由這些頁面構建的DOM樹進行兩兩比較,就可以盡可能地排除這些干擾信息,縮小下一步處理的數據集合,提高信息抽取的效率和精度。DSE算法的基本過程如下:
(1)深度優先遍歷兩棵待比較的樹A、B。其中樹A、B是由兩個相似的Web頁面構建所得。
(2)在遍歷的同時,不斷比較兩棵樹上相同位置的兩個節點,對于相同的兩個內部節點,則繼續比較它們的子節點。對于葉子節點,如果比較結果相同,則把它們從該樹上刪除;如果不同,則繼續比較下一個葉子節點。只有當一個節點的所有子節點都被刪除后,才會刪除該節點。
(3)當遍歷整棵樹后,樹A、B中重復出現的與主題無關節點均已被刪除。
圖2顯示了一個簡單的DSE算法的DOM樹比較過程。可以看到,樹A經一次DSE算法比較后,一部分與主題信息無關的重復內容已被刪除,頁面A對應的DOM樹已得到了很大程度的簡化。
2 抽取算法及實現
2.1 抽取算法
本文進行的信息抽取算法具體步驟如下:
(1)構建目標頁面的DOM樹。由網上獲得的目標頁面的HTML源文件并構建其對應的DOM樹。
(2)獲取目標頁面的幾個相似頁面。可利用正則表達式匹配等方法判斷是否屬于目標頁面的相似頁面。
(3)用DSE算法對目標頁面與其相似頁面進行比較匹配,簡化待抽取的目標頁面,具體的比較次數需要看頁面的復雜程度,一般為1~3次。只有盡可能地簡化目標頁面的DOM樹,縮小下一步處理的數據集合,才能有效提高抽取算法的速度和效率。
(4)在簡化后的DOM樹上進行遍歷,尋找信息量最大的節點,并生成從根到該節點的XPath。
(5)由XPath生成抽取規則和模板,并儲存相關模板信息,用于今后該類頁面的信息抽取。
(6)用生成的規則完成信息抽取,并把數據保存到數據庫中。
2.2 系統的實現
如圖3所示,根據設計目標,將系統分為以下模塊:
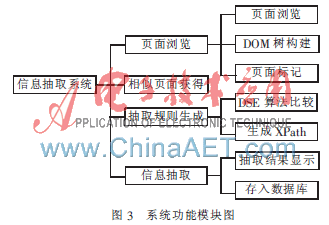
(1)頁面瀏覽模塊:實現用戶對Web頁面的瀏覽和標記功能。用戶可以在內置的瀏覽器中訪問該頁面,也可以在頁面中進行標記。同時,在界面上方構建生成的DOM樹中,也可以對各節點進行選擇查看和標記。
(2)相似頁面獲得模塊:獲得與目標頁面模板相同、結構一致的頁面,用于后續的抽取規則訓練算法。
(3)抽取規則生成模塊:用DSE算法進行相似頁面的比較訓練,尋找待抽取信息所在的節點,生成XPath,形成抽取規則。
(4)信息抽取模塊:由抽取規則進行抽取,顯示結果,并存入數據庫。
本信息抽取系統具體實現使用Java編程,以Java Swing制作界面。運行程序后,可以輸入任意網址打開頁面,并生成該頁面的DOM樹于界面左上方。比如,輸入http://www.sina.com.cn后,信息系統抽取主界面如圖4所示。
2.3 實驗結果及分析
為了驗證本算法的有效性,運用本系統對新浪、搜狐等網站的近千個新聞頁面進行了試抽取,并人工檢驗了抽取的有效性。實驗結果表明,大約98.2%的頁面都能正確抽取頁面的主題信息,只有極少數的頁面抽取失敗或無法抽取。可見,本抽取算法具有一定的推廣應用價值。
本文提出了一種基于樹比較的Web頁面主題信息抽取算法,該算法能快速、準確、有效地抽取目標頁面的主題信息。如何將該算法更好地應用于信息檢索、數據挖掘的各方面是今后的主要工作。如應用于搜索引擎的搜索算法中,提高搜索引擎的檢索速度和精度;或對已獲得的頁面信息進行進一步的數據挖掘,以發現其中有用的信息和知識。
參考文獻
[1] 孫承杰,關毅.基于統計的網頁正文信息抽取方法的研究[J].中文信息學報,2004,18(5):17-22.
[2] 張彥超,劉云,李勇,等.基于自動生成模板的Web信息抽取技術[J].北京交通大學學報,2009,33(5):40-45.
[3] 祝偉華,盧熠,劉斌斌.基于HMM的Web信息抽取算法的研究與應用[J].計算機科學,2010,37(2):203-206.
[4] DALVI N, BOHANNON P, SHA F. An approach based on a probabilistic tree-Edit model[A]. Proceedings of the 35th SIGMOD International Conference on Management of Data(SIGMOD’09)[C]. New York:ACM Press,2009:335-348.
[5] Wang Jiying, FRED H. LOCHOVSKY.Data-rich section extraction from HTML pages[A]. Proc 3rd International Conference on Web Information System Engineering (WISE’02)[C].Singapore:IEEE Computer Society Press,2002:1-10.