
摘 要:介紹了重排序緩沖器實(shí)現(xiàn)思想與硬件結(jié)構(gòu),并提出了增加結(jié)果鎖存器和將重排序緩沖器由集中式改為分布式的設(shè)計(jì),來(lái)降低重排序緩沖器設(shè)計(jì)復(fù)雜度的方案。
關(guān)鍵詞:重排序緩沖器;寄存器重命名;超標(biāo)量;亂序執(zhí)行;低復(fù)雜度
?
隨著科技的發(fā)展,人們對(duì)計(jì)算機(jī)處理速度的要求越來(lái)越高。為了提高微處理器的性能,人們提出了超標(biāo)量流水線技術(shù)。超標(biāo)量技術(shù)是指CPU在每個(gè)時(shí)鐘周期內(nèi)可以完成一條以上指令的并行執(zhí)行技術(shù)[1]。實(shí)現(xiàn)多指令并行執(zhí)行的關(guān)鍵在于亂序執(zhí)行。亂序執(zhí)行是指不按照指令原始順序執(zhí)行的技術(shù)。而實(shí)現(xiàn)指令亂序執(zhí)行的關(guān)鍵是用到了寄存器重命名技術(shù)。寄存器重命名是用一個(gè)或者多個(gè)虛擬寄存器來(lái)代替真實(shí)的數(shù)據(jù)寄存器的硬件猜測(cè)方法。重排序緩沖器ROB(Reorder Buffer)是超標(biāo)量處理器中基于寄存器重命名技術(shù)的一種實(shí)現(xiàn)結(jié)構(gòu),在MIPS R10000、Intel Pentium系列處理器和IBM Power系列處理器中得到了廣泛的應(yīng)用。
本文在介紹重排序緩沖器原理和實(shí)現(xiàn)的基礎(chǔ)上,分析了重排序緩沖器的復(fù)雜度問(wèn)題,即重排序緩沖器是一個(gè)占用大量寄存器資源并且有多個(gè)并行讀寫(xiě)端口的復(fù)雜器件,耗費(fèi)大量的功耗,容易出現(xiàn)不必要的延時(shí)。文中通過(guò)適當(dāng)?shù)母倪M(jìn)方法,優(yōu)化了重排序緩沖器的結(jié)構(gòu)和性能。
1 超標(biāo)量處理器中的寄存器重命名技術(shù)
1.1?超標(biāo)量處理器
現(xiàn)今的超標(biāo)量處理器都是通過(guò)一個(gè)時(shí)鐘周期內(nèi)發(fā)射多條指令并且亂序執(zhí)行這些指令來(lái)實(shí)現(xiàn)多指令并行技術(shù)的。
一般流水線技術(shù)的局限在于采用了按序發(fā)射指令的機(jī)制,指令必須按照原來(lái)的順序執(zhí)行。即如果流水線中出現(xiàn)停頓,那么后續(xù)指令則無(wú)法前行。因此,若2條緊挨著的指令存在相關(guān)關(guān)系就會(huì)引起停頓。對(duì)于有多個(gè)功能部件的機(jī)器,會(huì)造成這些功能的閑置。亂序執(zhí)行技術(shù)允許指令不按照原來(lái)的發(fā)射順序執(zhí)行,哪條指令的操作數(shù)已經(jīng)就緒,就可以提前執(zhí)行。這樣可有效提高指令的執(zhí)行效率。
1.2?寄存器重命名
亂序執(zhí)行帶來(lái)的數(shù)據(jù)相關(guān)和控制相關(guān)的問(wèn)題,實(shí)質(zhì)上是由于使用了共同的寄存器資源保存了不同的變量值所引發(fā)的[2]。若采用更名的方法,用2個(gè)不同的寄存器來(lái)保存這2個(gè)變量,出現(xiàn)相關(guān)的2條指令就能并發(fā)執(zhí)行,不會(huì)引起性能的損失。Tomasulo算法就是一種基于寄存器重命名的動(dòng)態(tài)調(diào)度算法,并在超標(biāo)量流水線中得到廣泛應(yīng)用。
2?重排序緩沖器的分析及相關(guān)問(wèn)題的提出
2.1?重排序緩沖器的原理
亂序執(zhí)行會(huì)帶來(lái)數(shù)據(jù)沖突和控制沖突,數(shù)據(jù)沖突問(wèn)題可以單純地采用保留站的調(diào)度技術(shù)予以解決,控制沖突的解決則要利用分支預(yù)測(cè)技術(shù),而分支預(yù)測(cè)常常會(huì)帶來(lái)預(yù)測(cè)的失敗。如果僅僅允許亂序執(zhí)行而不順序?qū)懟氐脑挘蜁?huì)出現(xiàn)不可恢復(fù)的預(yù)測(cè)失敗。因此,在Tomasulo算法的基礎(chǔ)上,又采用了一種基于硬件的猜測(cè)技術(shù)—重排序緩沖器。
重排序緩沖器本質(zhì)上也是一種寄存器重命名技術(shù),重排序緩沖器提供了額外的寄存器,就像Tomasulo算法中的保留站擴(kuò)展了寄存器堆一樣。重排序緩沖器在指令執(zhí)行結(jié)束和指令提交之間保存指令的執(zhí)行結(jié)果。因此,重排序緩沖器可以為指令提供源操作數(shù),就像Tomasulo算法中的保留站一樣提供操作數(shù)[3]。在Tomasulo算法中,一旦一條指令寫(xiě)入它的執(zhí)行結(jié)果,任何后邊的指令都可以在寄存器堆中讀取該結(jié)果,在指令提交之前,數(shù)據(jù)寄存器不用得到更新,由重排序緩沖器在指令執(zhí)行完畢和提交之前提供操作數(shù)。如圖1所示,重排序機(jī)制類似于一種旁路機(jī)制,這樣可將在重排序緩沖器中保存的某個(gè)指令的結(jié)果送到等待它的執(zhí)行單元中,不用經(jīng)過(guò)數(shù)據(jù)寄存器[4]。

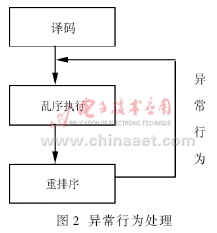
相比提供操作數(shù),重排序緩沖器另一個(gè)最大的作用是保證指令有序提交和異常行為恢復(fù)執(zhí)行[4]。提交階段必須按一開(kāi)始程序的最初順序提交結(jié)果到指定的存儲(chǔ)單元。在指令譯碼之后、亂序發(fā)射之前,每條指令已經(jīng)在重排序緩沖器中按序申請(qǐng)到存儲(chǔ)單元。當(dāng)指令執(zhí)行完畢,重排序緩沖器就可以保證最終結(jié)果順序提交。一旦出現(xiàn)中斷或異常行為,則廢除未提交的剩余所有執(zhí)行結(jié)果,進(jìn)入中斷處理或從正確的指令處重新開(kāi)始執(zhí)行。如圖2所示。
?
2.2?重排序緩沖器的硬件實(shí)現(xiàn)
重排序緩沖器是用于亂序執(zhí)行后恢復(fù)指令原來(lái)順序的一種硬件結(jié)構(gòu),以達(dá)到指令結(jié)果順序提交的目的。可以把重排序緩沖器看作是一個(gè)包含頭指針和尾指針的堆棧FIFO[5]。每條指令進(jìn)入流水線的時(shí)候,按照程序的最先順序都在重排序緩沖器中依次占據(jù)了一列條目,等指令執(zhí)行完畢,按照先入先出的順序依次提交指令。當(dāng)發(fā)生中斷或者異常行為時(shí),也能恢復(fù)原來(lái)的執(zhí)行順序。重排序緩沖器主要由下列幾個(gè)字段構(gòu)成:
(1) 指令字段:記錄指令;
(2) 目標(biāo)寄存器字段:記錄指令結(jié)果要寫(xiě)入的數(shù)據(jù)寄存器的地址;
(3) 數(shù)值字段:記錄指令的最后結(jié)果,如果結(jié)果還沒(méi)有得出,則記錄得出該結(jié)果的指令在ROB中的地址;
(4) 完成字段:記錄指令是否執(zhí)行完畢。
重排序緩沖器在超標(biāo)量流水線中的實(shí)現(xiàn)如圖3所示。運(yùn)算單元FU(Floating Unit)計(jì)算出結(jié)果后,將其寫(xiě)到重排序緩沖器中。同時(shí)通過(guò)前置定向總線FB(Forwarding? Bus)送給發(fā)射隊(duì)列IQ(Instruction Queue)中正在等待該操作數(shù)的指令。重排序緩沖器中存儲(chǔ)的結(jié)果將在指令退休時(shí)送給相應(yīng)的數(shù)據(jù)寄存器ARF(Architecture Register Files)中。在指令發(fā)射時(shí),操作數(shù)的值按照具體情況,既可以從數(shù)據(jù)寄存器中獲得,也可以從重排序緩沖器中獲得,如果值還沒(méi)有計(jì)算出來(lái),指令要在發(fā)射隊(duì)列中等待,直到前置定向總線將運(yùn)算結(jié)果送到發(fā)射隊(duì)列指定的位置。
?

?
3?重排序緩沖器的復(fù)雜性和優(yōu)化方案
3.1?重排序緩沖器的復(fù)雜性
這類的重排序緩沖器通常以允許多端口同時(shí)讀寫(xiě)的寄存器堆的方式實(shí)現(xiàn)。在一個(gè)N指令發(fā)射的超標(biāo)量流水線中重排序緩沖器至少需要2N個(gè)讀端口,以供N條指令可以在一個(gè)時(shí)鐘周期內(nèi)讀取所需要的2N個(gè)操作數(shù)。至少需要N個(gè)寫(xiě)端口,以供N條指令一個(gè)時(shí)鐘周期內(nèi)將結(jié)果寫(xiě)入重排序緩沖器中。
多端口寄存器堆的實(shí)現(xiàn)會(huì)加劇設(shè)計(jì)的復(fù)雜度,并且實(shí)際的端口數(shù)有時(shí)還會(huì)因?yàn)槌霈F(xiàn)雙倍位寬的操作數(shù)而加倍。在通常情況下,可以采用雙重排序緩沖器并行存在的方式,以減少每個(gè)重排序緩沖器端口的數(shù)量。但是,雙倍位寬和單倍位寬的數(shù)據(jù)常常一起存在,倘若采用雙ROB的形式將不可避免的帶來(lái)極大地浪費(fèi)。
另外,隨著端口數(shù)的增加,寄存器堆的面積也呈快速增長(zhǎng)趨勢(shì),這必將導(dǎo)致時(shí)序的延遲和功耗的增加。因此,合理地優(yōu)化重排序緩沖器的結(jié)構(gòu)設(shè)計(jì)日益成為人們關(guān)心的焦點(diǎn)。
3.2 重排序緩沖器結(jié)構(gòu)的優(yōu)化
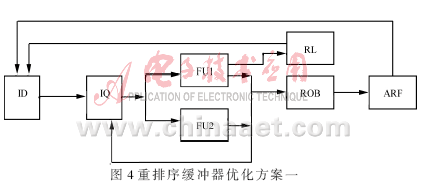
一個(gè)優(yōu)化的方法是去除重排序緩沖器上原操作數(shù)讀端口用以簡(jiǎn)化寄存器堆的設(shè)計(jì)。當(dāng)指令的結(jié)果從運(yùn)算單元送到重排序緩沖器中的同時(shí),通過(guò)前置定向總線送到指令發(fā)射單元中等待該操作數(shù)的指令隊(duì)列。之后,該操作數(shù)提交給數(shù)據(jù)寄存器,指令分配單元無(wú)法再?gòu)闹嘏判蚓彌_器中讀此操作數(shù)。當(dāng)操作數(shù)需要第二次被提取時(shí),而該操作數(shù)還沒(méi)有被提交給數(shù)據(jù)寄存器時(shí),常常會(huì)因?yàn)闊o(wú)法讀重排序緩沖器中的值,出現(xiàn)延遲,造成流水線的阻塞。因此,可以參考計(jì)算機(jī)中緩存Cache的設(shè)計(jì)方法,如圖4所示,加一個(gè)存儲(chǔ)單元數(shù)遠(yuǎn)少于重排序緩沖器的數(shù)據(jù)鎖存器RL(Retention Latches)以存儲(chǔ)指令結(jié)果,這樣執(zhí)行結(jié)束的指令結(jié)果在寫(xiě)入重排序緩沖器的同時(shí)也并行寫(xiě)入了數(shù)據(jù)鎖存器。為了在增加數(shù)據(jù)鎖存器的基礎(chǔ)上而不增加設(shè)計(jì)的復(fù)雜度,數(shù)據(jù)鎖存器的存儲(chǔ)量應(yīng)該盡可能的小,不妨采用LRU算法進(jìn)行鎖存器內(nèi)部數(shù)據(jù)的替換管理。LRU是廣泛應(yīng)用于計(jì)算機(jī)緩存Cache中的一種數(shù)據(jù)替換算法,為了減少替換那些可能不久要用到的信息,需要記錄數(shù)據(jù)塊的使用次數(shù)來(lái)預(yù)測(cè)未來(lái)的使用情況[6]。這樣在指令被重排序緩沖器提交給數(shù)據(jù)寄存器之前,數(shù)據(jù)鎖存器可以有效解決操作數(shù)延遲獲得的問(wèn)題。
?
另一個(gè)優(yōu)化的方法,從Tomasulo算法的分布式保留站中得到啟發(fā),將重排序緩沖器由集中式改為分布式,如圖5所示。這樣可以將一個(gè)多端口讀寫(xiě)的重排序緩沖器簡(jiǎn)化成多個(gè)單端口讀寫(xiě)的重排序緩沖器。這種方法簡(jiǎn)化了原來(lái)集中式寄存器堆多端口同時(shí)讀寫(xiě)的復(fù)雜度,但也帶來(lái)了因?yàn)槎鄠€(gè)分散的重排序緩沖器中指令提交的排序問(wèn)題。為此,可以在譯碼時(shí)給每一條指令加上標(biāo)志位,指明該指令在程序中的順序,并且標(biāo)注該指令發(fā)送給哪一個(gè)運(yùn)算單元。這樣,在每個(gè)緩沖器提交指令或者預(yù)測(cè)失敗時(shí),便能在多緩沖器間協(xié)調(diào)讀取指令或者結(jié)果。
?

3.3?性能分析
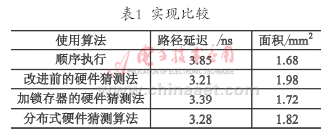
根據(jù)對(duì)各種模型的分析,列出表1中的順序執(zhí)行、改進(jìn)前的硬件猜測(cè)法以及改進(jìn)后的硬件猜測(cè)法3種實(shí)現(xiàn)形式,采用Verilog HDL語(yǔ)言對(duì)結(jié)構(gòu)進(jìn)行描述,采用Synopsy公司的Design Compiler工具在0.18 μm的CMOS工藝下進(jìn)行綜合和時(shí)序分析,得出性能的比較如表1所列。
?
從表1中可以看出,在普通的順序執(zhí)行算法下,硬件路徑延遲較大,但是面積最小;改進(jìn)前的硬件猜測(cè)算法路徑延遲最小,但是面積最大,帶來(lái)了設(shè)計(jì)上復(fù)雜度和功耗損失較大的問(wèn)題;采用改進(jìn)后的硬件猜測(cè)算法以后,雖然路徑延遲比改進(jìn)前大,但是面積相對(duì)減少很多,并且路徑的延遲相比順序執(zhí)行仍然減少了不少。因此,采用改進(jìn)后的硬件猜測(cè)算法在減少面積的情況下得到了可觀的效果。
超標(biāo)量處理器中的重排序緩沖器對(duì)于實(shí)現(xiàn)指令的亂序執(zhí)行和順序提交起著重要的作用。隨著對(duì)指令并行度要求的不斷提高,重排序緩沖器的設(shè)計(jì)結(jié)構(gòu)會(huì)越來(lái)越復(fù)雜。本文提出了幾點(diǎn)改進(jìn)方法,通過(guò)減少單個(gè)緩沖器上讀端口的數(shù)目,有效地降低了重排序緩沖器的設(shè)計(jì)復(fù)雜度,這對(duì)將來(lái)的超標(biāo)量處理器的設(shè)計(jì)有著深遠(yuǎn)影響。
參考文獻(xiàn)
[1]?STEVEN W, NADER B. Modeled and measured instruction fetching performance for superscalar microprocessors. IEEE transaction on parallel and distributed, 1998,9(6).
[2]?JOHN P,MIKKO H L.現(xiàn)代處理器設(shè)計(jì)——超標(biāo)量處理器基礎(chǔ)[M].北京:電子工業(yè)出版社,2004.
[3]?JOHN L H,DAVID A P.計(jì)算機(jī)系統(tǒng)結(jié)構(gòu)——量化研究方法(第3版)[M].北京:電子工業(yè)出版社,2004.
[4]?鄧正宏,康慕寧,羅旻. 超標(biāo)量微處理器的研究和應(yīng)用[J].微電子學(xué)與計(jì)算機(jī),2004,21(9):59-63.
[5]?TAREK M T, WILLS D S. An instruction throughput model of Superscalar Processors[J]. IEEE Transactions On Computers,2008,57(3).
[6]?李學(xué)干. 計(jì)算機(jī)系統(tǒng)結(jié)構(gòu)[M]. 西安:西安交通大學(xué)出版社,2007.