
射頻識別RFID (RadioFrequencyIdentification) 技術相對于傳統的磁卡及IC 卡技術具有非接觸、閱讀速度快、無磨損等特點, 在最近幾年里得到快速發展。RFID 系統主要由三部分組成, 即電子標簽(tag)、讀寫器(reader) 以及天線(antenna), 是一種非接觸式的自動識別系統。隨著RFID系統的不斷增多, 多個電子標簽同時將信號送入一個讀寫器的讀寫通道必然會產生信道爭用問題, 如何減少數據碰撞從而快速有效的在規定時間內讀取出所有電子標簽的信息成為一個難點。
解決碰撞問題的算法有ALOHA算法、分隙ALOHA算法和二進制樹形搜索算法, 但這幾種算法都有一個共同的缺陷: 信道利用率比較低。本文提出了一種新的反碰撞算法, 這種算法是在傳統的二進制樹算法基礎上, 通過迂回式反碰撞算法, 利用二進制位取值的互異(即非0 即1)的特性, 以及連續兩位發生沖突(即00, 01, 10, 11), 可同時識別出1~4 個標簽, 進而提高閱讀器識別標簽的效率, 在信道利用率上遠遠優于其它算法。
1 射頻識別系統的工作原理
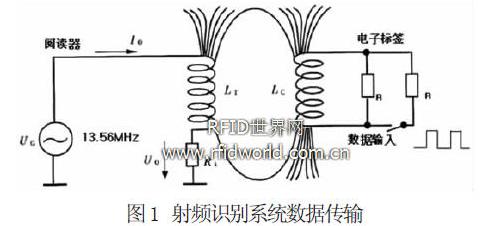
射頻識別系統的工作頻段有低頻, 中頻, 高頻, 超高頻及微波之分, 而在工業中通常采用13.56MHz 的頻率。對于從閱讀器與電子標簽間數據傳遞, 通常采用振幅鍵控ASK (AmplitudeShiftKeying)、頻移鍵控FSK(FrequencyShiftKeying)和相移鍵控PSK
(PHASEShiftKeying)。ASK 和PSK 常被使用, 因為它們特別容易解調, 其原理參見圖1。由圖1 中可知, 當有多于1個的標簽在閱讀器的作用范圍內時, 且傳遞的數據0/1 交錯時, 將會出現1個標簽諧振,
1個標簽失諧的情況。這時就閱讀器則很難通過判斷輸出端的高低電位來讀出標簽的內部信息, 這就是我們要解決的碰撞問題。
2 二進制搜索算法原理
二進制搜索算法, 是以一個獨特的序列號(UID)來識別標簽為基礎的, 為了能辨認出閱讀器中數據碰撞比特位的準確位置, 傳統采用曼徹斯特編碼。該編碼采用電平的上升沿和下降沿來表示數值位。本文中假設上升沿編碼為邏輯“0”, 下降沿編碼為邏輯“1”, 若狀態跳變, 視為無效數據且作為錯誤碼被識別。如在多標簽的環境中當同時有上升沿和下降沿同時存在是, 則會互相抵消從而無狀態跳變, 以此閱讀器判斷發生碰撞的準確位數而再次搜索。假設有6 個RFID 標簽, 其相應EPC代碼為8 位, 利用曼徹斯特編碼能準確識別出碰撞位的示意圖如圖2 所示, 圖中用紅色部分為碰撞位。

從圖中可知, 閱讀器檢測出D2, D3, D4, D6, D7 位出現碰撞,從而可以判斷出在同一區域內存在多個RFID標簽。
本文約定在閱讀器作用范圍內的所有標簽能在同一時刻同步傳送響應數據, 以便準確地監測碰撞位的發生。為了便于表述算法, 還需要引入4 種命令:
1) REQUEST: 表示閱讀器發送一個呼叫參數給區域內標簽, 所有標簽的EPC 與之進行“與運算”, 結果全為0
的標簽將各自的EPC返回至閱讀器。在第1 次詢問時, 呼叫參數應全為0, 即Request 命令為: Request(00000000),
這樣區域內所有標簽都會應答。
2) SELECT: 用某個(事先確定的) EPC 作為參數發送給標簽。具有相同EPC
的標簽將以此作為執行其他命令(例如讀出和寫入數據)的切入開關, 即選擇這個標簽。
3) READ/DATA: 選中的標簽將存儲的數據發送給閱讀器)。
4) UNSELECT: 取消一個事先選中的標簽, 標簽進入“休眠”狀態。在該狀態下標簽對收到的REQUEST 命令不作應答。為了重新激活標簽,
須將標簽移出閱讀器的作用范圍再進入, 以實行復位。
3 算法原理
假設閱讀器作用范圍內有6 個標簽, 閱讀器在本文約定的環境中識別這些標簽, 最初閱讀器對區域內標簽處于未知狀態,
發送Request(00000000) 命令, 此時閱讀器周邊區域內所有的標簽則同步應答。詳細數據處理過程如下:
Step1: 閱讀器發送Request (00000000) 命令。區域內所有標簽的與運算結果全為0, 即所有的標簽返回自身8 位的EPC
代碼應答。根據曼徹斯特編碼原理, 可解碼得EPC 數據為: “$$1$$$10”, 即D2, D3, D4, D6, D7
位發生碰撞。算法作以下的處理: 從5 個碰撞位隨機選擇一位, 如D7; 然后將上一次Request命令中的參數00000000 的D7 位取反,
得下一次Request 命令所需的參數: 10000000。
Step2: 閱讀器發送Request (10000000) 命令。則此時區域內D7位是0 的標簽應答, 即標簽1 不相應, 標簽2~ 標簽6
應答, 同理可解碼得EPC 數據為: “0$1$$$10”, 碰撞位有: D2, D3, D4, D6, 位。算法作以下的處理: 從4
個碰撞位隨機選擇一個, 如D3; 然后將上一次Request 命令中的參數10000000 的D3 位取反, 得下一次Request命令所需的參數:
10001000。
Step3: 閱讀器發送Request (10001000) 命令。區域內的D3 和D7 都是0 的標簽應答, 此時只有標簽4 應答,
其他標簽不響應, 在這種情況下沒有碰撞位, 閱讀器可以直接將收到的EPC 值用SELECT 命令發給標簽4 并進行讀寫操作,
處理完成后執行Unselect 命令, 屏蔽掉標簽4, 使它處于“休閑” 狀態。算法再采用回溯策略, 從該節點的父節點獲得下一次Request
命令所需的參數: 10000000。
Step4: 閱讀器發送Request ( 1000 0000) 命令。區域內D7 位是0 的標簽應答, 即標簽2, 標簽3, 標簽5, 標簽6
應答, 同理可解碼得EPC 數據為: 0$101$10, 碰撞位有: D2, D6, 位, 此時只有兩個碰撞位, 則讀寫器可依次通過SELECT
命令發送“00101010”,“00101110”, “01101010”, “01101110”, 從而完成標簽5, 標簽2, 標簽6
的讀寫操作, 最后通過UNSELECT 命令將些三個標簽置于“休閑” 狀態。算法再采用回溯策略, 從該節點的父節點獲得下一次Request
命令所需的參數: 00000000。
Step5: 閱讀器發送Request(00000000)命令。區域內所有處于非“啞吧” 狀態的標簽應答, 即標簽1 與標簽3 應答,
同理可解碼得EPC數據為: $0101010, 此時碰撞位只有D7 位。則讀寫器可依次通過SELECT命令發送00101010, 10101010,
從而完成標簽3 和標簽1 的讀寫操作, 最后通過UNSELECT 命令將標簽3 和標簽1 置于“休閑” 狀態。算法再采用回溯策略,
從該節點的父節點獲得下一次Request 命令所需的參數, 由于已到樹根無父節點, 因此識別過程結束。圖3 為識別讀寫全部標簽的流程圖:
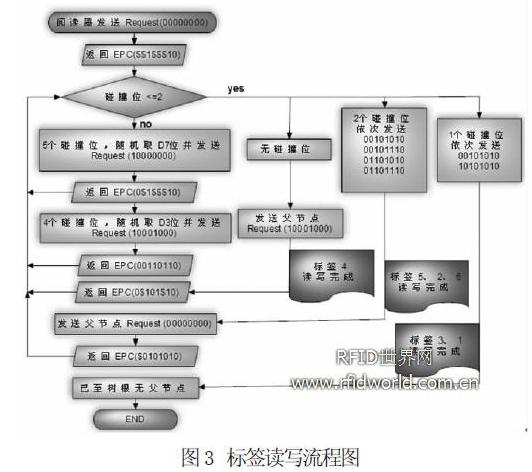
通過該實例, 可歸納該算法要點如下:
1) 閱讀器發Request (00000000) 命令, 要求區域內所有標簽應答。
2) 檢測有無碰撞發生。若無碰撞時, 可識別出一個單獨的標簽。標簽值為應答時返回的EPC 值。處理完后, 再屏蔽掉它。
3) 若有碰撞, 可分兩種情況, 如碰撞位>2, 則可從碰撞位中隨機選擇一位, 并由選中的那一位和上一次REQUEST 中的參數共同決定下一次Request 命令所需的參數, 具體如下: 在上一次REQUEST 命令中參數的基礎上再對所選中的那一位取反, 即可得下一次REQUEST命令的參數。
4) 若碰撞位<=2 時, 可通過改變相應兩位的數值即00, 01, 10, 11 的值以同時識別出4 個標簽, 另外下一次Request 命令所需參數, 采用回溯策略, 從其父節點獲得, 通過迂回方式直到執行Request(00000000)命令返回值碰撞位小于2 時讀寫結束。
4 系統的軟件實現
以下程序為實現讀寫過程的子程序:
Push(EPC): 將EPC 值入棧;
Pop(): 將棧頂元素彈出;
GetTop(): 返回棧頂元素;
StackEmpty(): 棧空返回true, 不空返回false;
Request(EPC): 閱讀器將EPC 發送給標簽;
GetCollisionBitsCount_(EPC): 返回EPC 值中碰撞位的數目;
RandomSelectCollisionBit(EPC): 返回從EPC 中隨機選擇的一個碰撞位的下標;
ReverseBit(EPC, n): 將EPC 的第n 位取反, 并返回取反后的EPC 值;
SetCollision(EPC, bit): 將EPC 的碰撞位置bit 值, 而其他位不變, 并返回。
閱讀器算法描述:
Push(00000000);
while(!stackEmpty())
{
Request(GetTop()); // 獲得返回的EPC 值;
if(GetCollisionBitsCount(EPC)>2)
Push(ReverseBit(GetTop(), RandomSelectCollisionBit(EPC)));
else
{
pop();
Switch(GetCollisionBitsCount(EPC))
Case0:
Select(EPC);
ReadData(EPC);
Unselect(EPC);
break;
Case1:
EPC0=SetCollision(EPC, 0);
Select(EPC0);
ReadData(EPC0);
Unselect(EPC0);
EPC0=SetCollision(EPC,1);
Select(EPC0);
ReadData(EPC0);
Unselect(EPC0);
break;
Case2:
for(i=0;i<4, i++)
{
EPC0=SetCollision(EPC,i);
Select(EPC0);
ReadData(EPC0);
Unselect(EPC0);
}
break;
}
}
5 算法復雜度和通信信道分析
本文這種迂回式算法受到標簽數量以及碰撞對數的限制, 假設n 個標簽中這樣無重疊的理想碰撞標簽對(任意兩組標簽對中無相同的標簽)有m (m≤n/2) 組, 則在最理想的情況下(這個要由好的隨機算法提供)算法的總的詢問次數為: R (n, m) =2 (n-m) -3。在本文基于迂回式的算法發送REQUEST 命令的次數為5 次(R (6, 2)), 而參考文獻[5]中提出的算法的詢問次數為7 次, 讀寫速度提高28%, 對于標簽較多的環境中將會高效完成讀寫動作。
6 結語
通過本文對標簽的處理過程可以看出讀寫過程實際上是請求與檢測的過程重復進行, 當碰撞位小于等于2 時可以快速高效的識別出標簽, 而當碰撞位大于2 時則通過屏蔽位的方式繼續發送請求命令直到碰撞位小于等于2, 正是通過反復迂回的方式從而大大減小了請求次數,提高了讀寫的速度, 從而實現了高效率的控制。