

文獻標識碼: A
文章編號: 0258-7998(2014)01-0016-04
FPGA作為未來數字電路系統的三大基石之一,是目前硬件設計方法的研究熱點。與傳統的電路設計方法相比,FPGA具有功能強、周期短、投資小、開發工具智能化等特點。隨著電子工藝的不斷改進,新一代的FPGA甚至集成了CPU和DSP內核,在一片FPGA上進行軟硬件協同設計,為實現片上可編程系統(SoPC)提供了強大的硬件支持,這使得FPGA成為許多高性能應用的最佳選擇。FPGA產品的應用領域已經從相對較窄的通信基礎設備領域迅速擴張到消費電子、汽車電子、工業控制、測試測量等領域。
一般來講,要在FPGA設計中實現較高的性能,除了要求設計者精通HDL語言,還需熟知FPGA的內部結構,具備足夠的數字電路知識。這種方法直接面向硬件,抽象層次較低,抬高了FPGA開發的準入門檻,還嚴重降低了FPGA的開發效率。
OpenCL作為跨平臺的開發語言,為上述問題提供了一套可選擇的解決方案。OpenCL在傳統的C語言基礎上進行了擴展,具備較高的抽象層次和可移植性,開發者即使不了解硬件電路和設備的底層細節,也可以開發出高性能的FPGA應用程序。這種開發方法可以減少硬件開發時間,把更多的時間用于算法優化,提高FPGA的開發效率。
目前,絕大部分OpenCL開發都是基于CPU和GPU。由于FPGA與GPU/CPU結構上的差異,OpenCL在GPU/CPU上的開發方法并不完全適用于FPGA,FPGA的OpenCL設計方法學尚存在較大的改進空間。針對以上問題,本文以矩陣乘法和QR分解為例,根據FPGA的特點制定并實現了多種優化方案,分析了各種優化方案的優缺點及適用情況,為后續FPGA的OpenCL開發提供參考。
1 相關工作
自2008年蘋果開發者大會(WWDC)提出OpenCL以來,已有不少的機構和學者進行OpenCL的開發研究,并取得了顯著的成果,目前大部分的OpenCL研究都是基于GPU平臺。參考文獻[1]就矩陣乘法分別在多核CPU、AMD GPU、NVIDIA GPU上進行了實現和優化,并對比了各平臺的性能。
2013年,Altera和Xilinx兩大FPGA主流廠商相繼推出了針對FPGA的OpenCL開發套件,但目前相關研究成果較少,只能在IEEE平臺上搜索到寥寥幾篇論文。參考文獻[2-4]中介紹了在FPGA上進行OpenCL開發的原理及相關工具。參考文獻[5]使用OpenCL在Altera的FPGA上實現了一個文檔篩選算法,與CPU、GPU相比分別取得了5.5、5.25的加速比,但沒有針對FPGA做深入的優化工作,也未詳細分析如何提升FPGA運算性能。參考文獻[6]分別在CPU、GPU和FPGA 3個平臺上實現了不規則圖像和視頻的壓縮算法,FPGA平臺與多核CPU、GPU相比分別達到了3、114的加速比。作者只是簡單地將GPU上的應用移植到了FPGA上,而未做進一步的優化。參考文獻[7]對多核CPU、GPU、FPGA平臺在性能、設計理論、平臺體系結構等方面進行了對比,分別用CUDA、OpenCL、VHDL 3種開發語言在多種平臺下實現了Quantum Monte Carto程序。通過對比發現,OpenCL可以很方便地在多核CPU、GPU和FPGA之間進行移植。
目前介紹在FPGA上進行OpenCL開發的相關文獻還非常稀少,大多數文獻都只是針對FPGA的OpenCL開發進行理論介紹,即使有少數幾篇進行了實際應用開發,也僅僅停留在實現階段,并沒有針對FPGA的硬件結構詳細分析其OpenCL優化方法,這正是本文的研究重點。
2 算法研究
目前基于FPGA的OpenCL開發都是移植了GPU上的應用,例如圖像處理、視頻壓縮/解壓縮等。然而通信、雷達、汽車電子、工業控制才是FPGA的傳統領域,尤其在通信領域中FPGA應用更為廣泛。但當前還沒有相關文獻把OpenCL開發方法用于通信領域。
矩陣運算是通信領域中的基礎運算,尤其是矩陣乘法和QR分解,是工程應用中最常見的矩陣運算,在信號檢測與估計、數字信號處理等領域中應用廣泛。因此,本文以矩陣乘法和QR分解為例,對FPGA的OpenCL實現及優化進行相關研究。



initial Q=E, R=A
barrier
for(int j=0; j<=Width-2; j++)
{
initial H
barrier
calculate the
generate H
barrier
compute Q = Q *
barrier
compute R = H * R
barrier
}
由于Householder變換法的特性,本文只將部分優化手段應用于QR分解。主要探索item復制和向量化兩種方法的性能。本例中的QR分解內部具有較多的數據同步點,且item之間的數據依賴性非常強,即邏輯控制較多,因而向量化和item復制并不是QR分解的理想優化手段。
4 結果分析
測試數據采用隨機函數生成,并將FPGA的運算結果與C函數的運算結果相比較,判斷結果是否正確。本文采用多種優化方法實現矩陣乘法,實驗結果如表1所示。

對于數據存取優化(如表1所示),通過設置合適的workgroup大小,減少item重復存取數據的次數,即可有效地提高性能。
對于循環展開優化,運行時間與循環展開次數是呈反比的。循環展開實質就是采用空間換取時間,展開次數越多,邏輯面積越大,執行時間則越短。
對于向量化1、2、4、8次,可以看出其運行時間基本是與向量化次數呈反比的。向量化復制了kernel的運算單元,使得item可以同時存取并處理多個數據,提高了kernel性能。然而,向量化16次的性能更差,這主要是受到了硬件資源限制。DDR帶寬和FPGA邏輯資源都已超出DE4的最高峰值,造成了性能的急劇下降。
隨著item復制次數的增加,性能有所提高,這也是使用空間換取時間的方法。但是其性能并不像向量化那樣呈線性增長,這是因為item復制是將整個kernel功能單元進行復制,除了需要較多的邏輯資源外,全局帶寬的需求也成倍增長,導致全局帶寬超過DDR的最大帶寬,使得性能增長曲線是非線性的。
組合優化同時使用向量化和item復制,可最大限度地發揮這兩種方法的優點,實現性能提升,但效果還不夠顯著,這也是受到了DDR帶寬的限制。
矩陣乘法是典型的大數據運算,有著大量的數據存取操作,內部控制邏輯較少,這類運算需要較大的全局帶寬和較強的浮點運算能力。從表1中可以看到性能提升的瓶頸在于全局帶寬,如何解決這一問題是優化的重點。可以使用以下兩種方法降低kernel所需的全局帶寬:(1)進行數據存取優化,減少kernel的重復存取操作,減少單個item實際使用的帶寬;(2)向量化,提高全局帶寬的有效利用率。從表1中也可以看出,這兩種方法確實取得了非常好的效果。另外,還可以通過提升硬件的全局帶寬來滿足kernel對帶寬的需求。
在QR分解中,主要采用了向量化和item復制兩種方法,如表2所示。
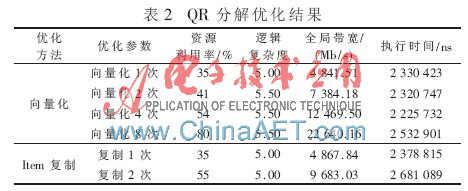
由表2可見,不管是向量化還是item復制,性能均沒有得到有效的提升,甚至有一定的惡化,其中item復制帶來的性能惡化更嚴重,這主要是因為QR分解的邏輯復雜度較大。在QR分解中,數據量并不大,所需的全局帶寬較小,除了向量化8次外,其余的優化所需的全局帶寬均沒有超過DE4的限制。但是其中的運算過程較為復雜,可以看到其邏輯復雜度為5.5左右,限制了kernel性能的提高。
對于此類邏輯復雜度較大的應用,上述幾種優化手段均不能得到非常好的效果。此時應以算法優化為主,以降低kernel內部的邏輯復雜度。
本文以矩陣乘法和QR分解為例,在FPGA上分別進行了實現和優化,比較分析了各種優化方法的優缺點及適用范圍。目前,FPGA的OpenCL開發剛剛興起,還有諸多不足,從實驗中也可以看出,許多優化方法都受到了FPGA結構、算法并行性等多方面的限制,還需要從設計方法、FPGA結構優化、算法優化等多個方面進一步探討如何更合理地運用OpenCL開發FPGA。這有賴于FPGA廠商進一步完善工具和開發流程,也有賴于廣大科研工作者、應用工程師的配合和努力。
參考文獻
[1] SEO S,JO G,LEE J.Performance tuning of matrix multiplication in OpenCL on different GPUs and CPUs[C].High Performance Computing,Networking,Storage and Analysis,2012:396-405.
[2] CZAJKOWSKI T S.Form OpenCL to high-performance hardware on FPGAs[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:531-534.
[3] Ma Sen,Huang Miaoqing,ANDREWS D.Developing application-specific multiprocessor platforms on FPGAs[C].Reconfigurable Computing and FPGAs(ReConFig),2012 International Conference,2012:1-6.
[4] ECONOMAKOS G.ESL as a Gateway from OpenCL to FPGAs:basic ideas and methodology evaluation[C]. Informatics(PCI),2012 16th Panhellenic Conference,2012:80-85.
[5] CHEN D,SINGH D.Invited paper:using OpenCL to evaluate the efficiency of CPUS, GPUS and FPGAS for information filtering[C].Field Programmable Logic and Applications(FPL),2012 22nd International Conference,2012:5-12.
[6] CHEN D,SINGH D.Fractal video compression in OpenCL:an evaluation of CPUs,GPUs,and FPGAs as acceleration platforms[C].Design Automation Conference(ASP-DAC),2013 18th Asia and South Pacific,2013:297-304.
[7] WEBER R.Comparing hardware accelerators in scientific applications:a case study[J].Parallel and Distributed Systems,IEEE Transactions,2011,22(1):58-68.
[8] 張賢達.矩陣分析與應用[M].北京:清華大學出版社,2004.
[9] 李剛強,田斌,易克初.FPGA設計中關鍵問題的研究[J].電子技術應用,2003,29(6):68-71.
[10] 張國禮,王建業,肖宇.浮點矩陣相乘IP核并行改進的設計與實現[J].電子技術應用,2012,38(2):43-46.