
摘 要: 從節約FPGA資源的角度出發,分析了超高速條件下多協議" title="多協議">多協議支持策略的實現難點,設計了一種可支持10Gbps" title="10Gbps">10Gbps速率下多協議報文線速轉發的引擎結構,解決了FPGA“資源與速度互換”的矛盾。
關鍵詞: 路由器 轉發引擎" title="轉發引擎">轉發引擎 協議
光纖傳輸技術發展迅速,網絡鏈路層的接口速率目前已達到10Gbps,出現了諸如10G的LAN、WAN、POS等接口類型。高端路由器作為骨干網的核心交換結點,必須支持10Gbps接口,轉發引擎的單包處理時間將急劇縮短。
另一方面,隨著IPv6、組播" title="組播">組播、MPLS協議的成熟及廣泛應用,高端路由器也要求提供對以上協議的支持。而不同類型的報文處理流程不盡相同,很難實現通用模塊的處理。這無疑增加了超高速轉發引擎的設計難度。
傳統的報文處理流程已不能滿足超高速轉發和多協議支持的要求。作為轉發處理的代表方向之一,網絡處理器(NP)目前的商用化水平還不支持10Gbps接口,大多不具備多協議支持的能力。
同時,從自主知識產權的角度出發,也必須在高端路由器上開發自己的轉發“芯”。
本文在深入分析了轉發引擎的實現難點后,從提高報文處理速度和節省FPGA資源的角度出發,設計了一種可支持多協議的超高速轉發引擎結構,并經國家“863”課題(“大規模接入匯聚路由器ACR”)工程驗證,可支持10Gbps接口下多種類型報文的線速轉發。
1 10Gbps接口下的線速轉發
表1給出了不同接口下,40字節超短包的線速轉發時間。

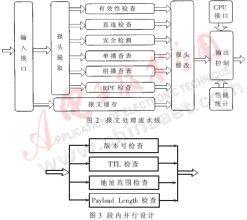
對于40字節的超短包,10Gbps接口下的處理時間只有32ns,即使在100MHz時鐘下,也只有不到4個周期的時間。而轉發引擎的報文處理流程包括報頭有效性檢查、直連檢查、組播RPF檢查、查表" title="查表">查表(單、組播、MPLS查表)、報頭修改等復雜操作。傳統的串行處理流程顯然無法滿足線速轉發的時間要求。
1.1 并行流水線方案
按照處理流程各步驟之間的時間關系,筆者在對整個處理流程進行了功能劃分后,采用流水線設計,縮短了處理時間,如圖1。

引進該方案的最大好處是:整個轉發引擎可以處于流水線狀態,不必等待單個任務的完成,省去了串行處理中的等待時間。整個流水線的周期等于最長流水段的周期(路由查表),而不是簡單的各段周期之和。
按照這個思路,在實際工程應用時,采用了如下并行流水線引擎結構:
對某些流水段,可以通過段內的并行設計,進一步縮短處理時間。例如,對圖2中的有效性檢查模塊,可以進一步細化為版本號檢查、TTL檢查、地址范圍檢查、Payload Length檢查四個子模塊,作并行處理,如圖3。
1.2 方案分析
采用并行流水線的設計,其關鍵在于整個流水線的不斷流、不溢出。這要求對各流水段進行精細劃分,使各段的周期盡量接近,即實現同步流水線,減少段間的緩存容量。
2 多協議支持策略
本方案考慮支持的協議為IPv4、IPv6、MPLS,均含單播、組播、二次查表。要支持如此多的協議類型,而不同類型報文的處理流程不盡相同,在時序上很難對齊,難以用通用模塊實現,必然需要大量的緩存FIFO。圖4給出了其分析。

可以看出,報頭處理的設計非常復雜,資源占用較多。為了合理利用FPGA的內部資源,必須對報頭處理單元精心設計。
報頭處理單元要處理的報文包括以下類型:IPv4(單、組播)、IPv6(單、組播)、MPLS(單、組播)6種,加上二次查表,共有12種類型的報文。對此,有如下分析:
(1)對以上的12種情況各用一個單元進行實現,這就意味著報頭處理中任何一處的緩存FIFO都必須生成12個。
(2)粗略劃分成IPv4、IPv6和MPLS三種實現單元,每一個單元又采用單組播獨立實現的方式,也就是將二次查表和非二次查表的報頭處理做成通用處理方式。這樣也需要6套FIFO緩存報文。
(3) 只分成IPv4、IPv6和MPLS三種情況,對單播和組播、二次查表以及非二次查表做成通用的處理模塊,這樣內部需要3套緩存FIFO。
(4) 與(3)的區別在于,通過精細設計報頭處理單元的各種讀寫信號(上報、轉發、二次查表),使得報頭處理單元內部不需要緩存報文,報頭處理主要完成生成內部報頭(轉發、上報和二次查表),將緩存FIFO合并為一個,不管是IPv4、IPv6還是MPLS共用一個轉發FIFO和上報FIFO。
為節省FPGA資源,提高設計可靠性,筆者在實際工程中采用了方案(4)的設計方法。其實現結構如圖5。
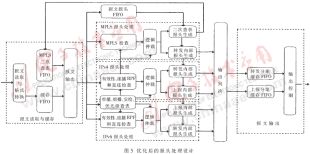
方案分析:顯然,該設計方案在節省資源的同時,復雜了內部邏輯的設計,因為任何一個報頭處理都需要同時完成單播和組播、非二次查表和二次查表的統一處理,而且各種報文都統一存放于一個緩存FIFO,因此還需要IPv4、IPv6和MPLS報頭處理單元中的轉發設計和上報設計進行時序對齊,即從緩存FIFO讀出報文的同時送往轉發和上報,供兩路同時使用(在轉發和上報都有效時),需要二者的時序進行配合。
3 工程應用
該方案已應用在“大規模接入匯聚路由器ACR”的10G轉發引擎上,采用的FPGA為VIRTEX PRO系列的XC2VP70芯片。圖6給出了測試數據。

分析:
(1) 單一包長測試條件下,在負荷為100%時,當包長大于等于109.5字節時的丟包率低于1.07E×10-6,吞吐率接近于1。
(2) 混合包傳輸條件下,在端口負荷低于90%時,丟包率低于3.0E×10-4。
本文著重結合項目需要,解決了10Gbps線速轉發和多協議支持兩個問題。通過并行流水線設計,縮短了報文處理時間。而通過報頭處理內部各模塊的時序配合,減少了FPGA內部緩存FIFO的使用,節省了FPGA資源,保證了該設計的工程實用性。方案的難點在于報頭綜合處理單元的時序邏輯設計。
可以預見,鏈路接口速率即將突破40Gbps,可以考慮采用多條類似流水線并行處理的引擎結構,但將面臨流量均衡及轉發表效率的問題,這是下一步的研究方向之一。
參考文獻
1 Xilinx Corporation.RocketIO transceiver user guide[Z].UG024 (v2.3.2)June 24,2004
2 Xilinx Corporation.Virtex pro platform FPGA handbook.2003
3 Mohammad J.Akhbarizadeh and mehrdad nourani. An IP packet forwarding technique based on partitioned lookup table
4 Newman P, Minshall G, Huston L. IP switching and gigabitrouters.