
??? 摘? 要: 針對在FPGA中實現FIR濾波器的關鍵——乘法運算的高效實現進行了研究,給出了將乘法化為查表" title="查表">查表的DA算法,并采用這一算法設計了FIR濾波器。通過FPGA仿真驗證,證明了這一方法是可行和高效的,其實現的濾波器的性能優于用DSP和傳統方法實現的FIR濾波器。最后介紹了整數的CSD表示和還處于研究階段的根據FPGA實現的要求改進的最優表示。?
??? 關鍵詞: FPGA? DA? FIR濾波器? CSD
?
??? 數字濾波器" title="數字濾波器">數字濾波器是語音與圖像處理、模式識別、雷達信號處理、頻譜分析等應用中的一種基本的處理部件,它能滿足濾波器對幅度和相位特性的嚴格要求,避免模擬濾波器所無法克服的電壓漂移?溫度漂移和噪聲等問題。有限沖激響應(FIR)濾波器能在設計任意幅頻特性的同時保證嚴格的線性相位特性。?
??? 目前FIR濾波器的實現方法有三種:利用單片通用數字濾波器集成電路?DSP器件和可編程邏輯器件實現。單片通用數字濾波器使用方便,但由于字長和階數的規格較少,不能完全滿足實際需要。使用DSP器件實現雖然簡單,但由于程序順序執行,執行速度必然不快。FPGA有著規整的內部邏輯陣列和豐富的連線資源,特別適合于數字信號處理" title="數字信號處理">數字信號處理任務,相對于串行運算為主導的通用DSP 芯片來說,其并行性和可擴展性更好。但長期以來,FPGA一直被用于系統邏輯或時序控制上,很少有信號處理方面的應用,其原因主要是因為在FPGA中缺乏實現乘法運算的有效結構。現在這個問題得到了解決,使FPGA在數字信號處理方面有了長足的發展。?
1 分布式運算原理?
??? 分布式算法" title="分布式算法">分布式算法(DA)早在1973年就已經被Croisier提出來了,但是直到FPGA出現以后,才被廣泛地應用在FPGA中計算乘積和。?
??? 一個線性時不變網絡的輸出可以用下式表示:?
??? 
??? 假設系數c[n]是已知常數,x[n]是變量,在有符號DA系統中假設變量x[n]的表達式如下:?
??? 
式中,xb[n]表示x[n]的第b位,而x[n]也就是x的第n次采樣。于是,內積y可以表示為:?
??? 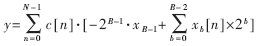
??? 重新分別求和(也就是分布式算法的由來),其結果如下:?
??? 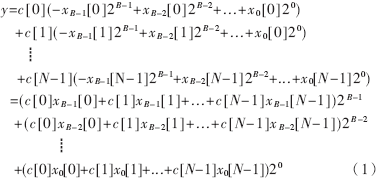
??? 從(1)式可以發現,分布式算法是一種以實現乘加運算為目的的運算方法。它與傳統算法實現乘加運算的不同在于執行部分積運算的先后順序不同。分布式算法在實現乘加功能時,是通過將各輸入數據的每一對應位產生的部分積預先進行相加形成相應的部分積,然后再對各個部分積累加形成最終結果的,而傳統算法是等到所有乘積已經產生之后再來相加完成乘加運算的。與傳統串行算法相比,分布式算法可極大地減少硬件電路的規模,提高電路的執行速度。它的實現框圖如圖1(虛線為流水線寄存器)所示。?
?

?
2 用分布式原理實現FIR濾波器?
2.1 串行方式?
??? 當系統對速度的要求不高時,可以采用串行的設計方法,即采用一個DA表?一個并行累加器和少量的寄存器就可以了。?
在用LUT實現串行分布式算法的時候,假設系數為8位,則DA表的規模為2N×8位。可以看到如果抽頭系數N過多,則DA表的規模將十分龐大。這是因為LUT的規模隨著地址空間的變化(也就是N的增加)而呈指數增加。例如EPF10K20包含1152個LC,而一個27×7位的表就需要394個LC[2]。當N過大時,一個FPGA器件就不夠用了。?
??? 為了減小規模,可以利用部分表計算,然后將結果相加。假定長度為LN的內積為:?
??? 
??? 將和分配到L個獨立的N階并行DA的LUT之中,結果如下:?
??? 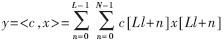
??? 如圖2所示,實現一個4N的DA設計需要3個次輔助加法器。表格的規模從一個24N×B位的LUT降到4個2N×B的位表。?
?
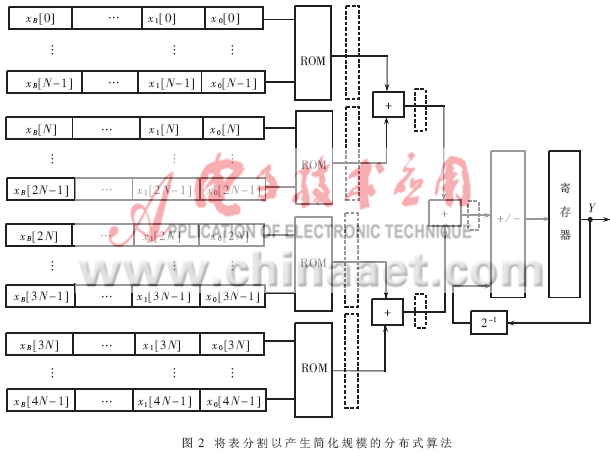
?
??? 如果再加上流水線寄存器,由于EPF10K20每個LC后面都跟有一個寄存器,所以并沒有增加電路規模,而速度卻得到了提高。?
2.2 并行方式?
??? 采用并行方式的好處是處理速度得到了提高。由于數據是并行輸入,所以計算速度要比串行方式快,但它的代價是硬件規模更大了。下面舉出全并行的例子。?
??? 設 ? sum[0]=c[0]x0[0]+c[1]x0[1]+...+c[N-1]x0[N-1]?
???????? sum[B-1]=c[B-1]xB-1[0]+c[1]xB-1[1]+...+c[N-1]xB-1[N-1]?
??? 可將(1)式改寫成如下形式:?
??? y=sum[0]+sum[1]21+sum[2]22+...+sum[B-1]2B-1???? (2)?
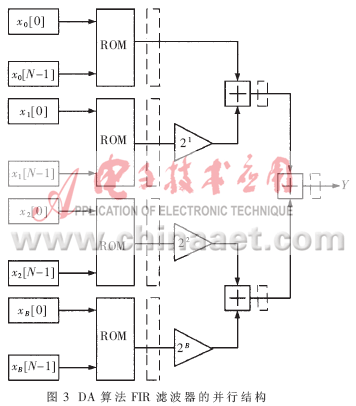
??? 利用式(2)可得一種直觀的加法器樹,如圖3所示。?
?
?
??? 雖然硬件規模加大了,但是如果把系數的個數限制在4個或8個,再加上流水線寄存器,這個代價還是值得的。而且每張表都是相同的,不用為每個采樣都設計一張表,減小了設計量。?
??? DA算法的主要特點是巧妙地利用ROM查找表" title="查找表">查找表將固定系數的MAC運算轉化為查表操作,其運算速度不隨系數和輸入數據位數的增加而降低,而且相對直接實現乘法器而言在硬件規模上得到了極大的改善。利用ALTERA的FLEX10K實現的16階8位系數的并行FIR濾波器,其時鐘頻率可以達到101MHz,而實現的16階8位系數的串行FIR濾波器,其時鐘頻率可以達到63MHz,每9個時鐘周期可完成一次計算。但是其系數是傳統二進制的,造成了很大的冗余(對于用逐位相加法實現的乘法器,當系數有一位為零時不用相加,零位越多,冗余越大),而且查找表的大小隨著濾波器階數的增加成指數增加,雖然可以采用將大查找表分解為小查找表,但是無法從根本上解決這一問題,這些都是DA方法的缺點。后面將對FIR濾波器實現給出新的設計方法,進一步降低邏輯資源的消耗。?
3 CSD碼及最優化方法?
??? 一個整數X與另一整數Y的乘積的二進制表示可以寫成:?
??? 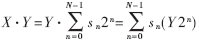
??? 對于標準二進制,由于sn=0時的對應項Y2n并不參與累加運算,所以可以用另一種表示方法使非零元素的數量降低,從而使加法器的數目減少,降低硬件規模。有符號數字量(SD)有三重值?邀0,-1,+1?妖,如果任意兩個非零位均不相鄰,即為標準有符號數字量(CSD)。例如:?
??? 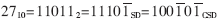
??? 可以證明CSD表示對給定數是唯一的并且是最少非零位的[3]。CSD表示相對于標準二進制表示的改進在于引入了負的符號位,從而降低了非零位個數,大大降低了邏輯資源的占用(大約平均降低33%的邏輯資源)[2]。?
??? 當用硬件實現時,常常限制系數位數,即每個系數與N個正(負)2的冪次之和近似。標準二進制數在整數軸上是緊密和均勻分布的,而CSD碼是非均勻分布的,其對實系數的量化誤差比標準二進制大[3],雖然增加N可以減小量化誤差,但是會增大邏輯資源的消耗;而且CSD表示無法應用流水線結構,從而降低處理速度。???
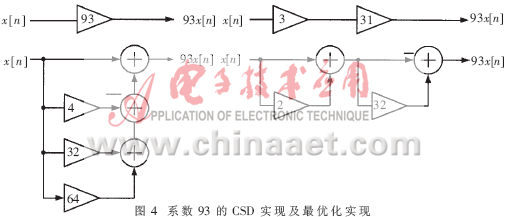
??? 還可采用優化的方法將系數先拆分成幾個因子,再實現具體因子。這就是最優化的代碼。例如對系數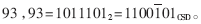 用最優化法,系數93可以表示成93=3·31,每個因子需要一個加法器,如圖4所示。?
用最優化法,系數93可以表示成93=3·31,每個因子需要一個加法器,如圖4所示。?
?
?
??? 從圖中可以看出,CSD碼需要三個加法器,而最優法只需要兩個加法器;CSD碼的重要缺陷在于每一級加法都需要初節點參與,而最優表示僅依賴上一級加法的結果,因此也就更適合流水線處理。Dempster等人提出了需要1到4個加法器的所有可能配置表。利用這張表,就可以合成成本在0與4個加法器之間的所有8位二進制整數[4]。???
??? 本文首先給出了一種巧妙利用FPGA的查找表,將乘法轉化為查找表運算的DA算法,并用ALTERA的FLEX10K器件分別實現了一個8位16階的串行與并行FIR濾波器,系統頻率分別達到63MHz與101MHz,采樣速度分別達到7MSPS與101MSPS。而DSP實現的FIR濾波器只能達到5MSPS,明顯低于FPGA。用傳統的位串行方法實現的一個8階8位FIR濾波器,也只能達到5MSPS,明顯低于串行式DA方法;接著,針對系數的二進制表示非零位不是最少(即實現系數乘法的加法器不是最少)的問題,介紹了整數的CSD表示以及最優表示,它們可以用較小的代價和與加法器級數無關的處理速度實現整數乘法運算,能比DA方法用更少的邏輯資源實現FIR濾波器。這些算法都不同于傳統的設計觀念,為基于FPGA的DSP設計提出了新的思路,必將在高速FIR濾波器設計?高速FFT設計中得到廣泛的應用。隨著FPGA集成規模的不斷提高,許多復雜的數學運算已經可以用FPGA來實現,利用單片FPGA實現系統的設想即將變為現實。?
參考文獻?
1 ALTERA Data Book, 2001?
2 Uwe Meyer-Baese著, 劉 凌, 胡永生譯.數字信號處理的FPGA實現.北京:清華大學出版社,2003?
3 Shousheng He,Mats Torkelson.FPGA Implementation of FIR?Filters Using Pipelined Bit-serial Canonical Signed Digit?Multipliers. IEEE Custom Integrated Circuits Conference,?1994?
4 A.Dempster,M.Macleod.Use of Minimum-Adder Multiplier?Blocks in FIR Digital Filters. IEEE Transactions on Circuits and Systems II, 1995;42:569~577