
文獻標識碼: A
文章編號: 0258-7998(2010)08-0119-03
說話人識別又被稱為話者識別,是指通過對說話人語音信號的分析處理,自動確認說話人是否在所記錄的話者集合中,以及進一步確認說話人的身份。說話人識別的基本原理如圖1所示。
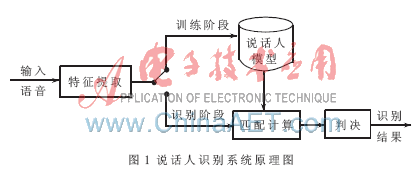
按照語音的內容,說話人識別可以分為文本無關的(Text-Independent)和文本相關的(Text-Dependent)兩種。文本無關的識別系統不規定說話人的發音內容,模型建立相對困難,但用戶使用方便。與文本有關的說話人識別系統要求用戶按照規定的內容發音,而識別時也必須按規定的內容發音,因此可以達到較好的識別效果。
隨著網絡技術的發展,通過Internet網絡傳遞語音的網絡電話VoIP(Voice over IP)技術發展迅速,已經成為人們日常交流的重要手段,越來越多的用戶拋棄傳統的通信方式,通過計算機網絡等媒介進行語音交流。由于VoIP工作方式的特點,語音在傳輸中經過了語音編譯碼處理,VoIP設備端口同時要處理多路、海量的壓縮話音數據。所以VoIP說話人識別技術主要研究的是如何高速、低復雜度地針對解碼參數和壓縮碼流進行說話人識別。
現有的針對編碼域說話人識別方法的研究主要集中在編碼域語音特征參數的提取上,香港理工大學研究從G.729和G.723編碼比特流以及殘差中提取信息,并采用了分數補償的方法。中國科學技術大學主要研究了針對AMR語音編碼的說話人識別。西北工業大學在說話人確認中針對不同的語音編碼差異進行了補償算法研究,并且研究了直接在G.729編碼的比特流中提取參數的方法。說話人模型則主要采用在傳統說話人識別中應用最廣泛的GMM-UBM(Gaussian Mixture Model-Universal Background Model)。GMM-UBM的應用效果和混元數目密切相關,在保證識別率的基礎上,其處理速度無法滿足VoIP環境下高速說話人識別的需求。
本文研究VoIP語音流中G.729編碼域的說話人實時識別,將DTW識別算法成功應用在G.729編碼域的文本相關的說話人實時識別。
1 G.729編碼比特流中的特征提取
1.1 G.729編碼原理
ITU-T在1996年3月公布G.729編碼,其編碼速率為8 kb/s,采用了對結構代數碼激勵線性預測技術(CS-ACELP),編碼結果可以在8 kb/s的碼率下得到合成音質不低于32 kb/s ADPCM的水平。 G.729的算法延時為15 ms。由于G.729編解碼器具有很高的語音質量和很低的延時,被廣泛地應用在數據通信的各個領域,如VoIP和H.323網上多媒體通信系統等。
G.729的編碼過程如下:輸入8 kHz采樣的數字語音信號先經過高通濾波預處理,每10 ms幀作一次線性預測分析,計算10階線性預測濾波器系數,然后把這些系數轉換為線譜對(LSP)參數,采用兩級矢量量化技術進行量化。自適應碼本搜索時,以原始語音與合成語音的誤差知覺加權最小為測度進行搜索。固定碼本采用代數碼本機構。激勵參數(自適應碼本和固定碼本參數)每個子幀(5 ms,40個樣點)確定一次。
1.2 特征參數提取
直接從G.729 編碼流中按照量化算法解量化可以得到LSP參數。由于后段的說話人識別系統還需要激勵參數,而在激勵參數的計算過程中經過了LSP的插值平滑,所以為了使特征矢量中聲道和激勵參數能準確地對應起來,要對解量化的LSP參數采用插值平滑。

本文選擇G.729編碼幀中第一子幀的LSP(1)參數的反余弦LSF及由其轉換得到的LPC、LPCC參數作為聲道特征參數。
參考文獻[1]發現識別特征加入G.729壓縮幀中的語音增益參數,說話人識別性能發生了下降。去除G.729壓縮碼流特征中的增益參數GA1、GB1、GA2、GB2,結果發現,當采用了去除增益參數的特征矢量方案X=(L0,L1,L2,L3,P1,P0,P2),識別性能得到了提高,所以本文最終采用的G.729壓縮碼流特征為X=(L0,L1,L2,L3,P1,P0,P2),共7維。
2 動態時間規整(DTW)識別算法
動態時間規整DTW(Dynamic Time Warping)是把時間規整和距離測度計算結合起來的一種非線性規整技術。該算法基于動態規劃思想,解決了發音長短不一的模版匹配問題。
算法原理:假設測試語音和參考語音分別用R和T表示,為了比較它們之間的相似度,可以計算它們之間的距離D[T,R],距離越小則相似度越高。具體實現中,先對語音進行預處理,再把R和T按相同時間間隔劃分成幀系列: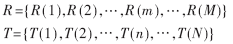
然后采用動態規劃進行識別。如圖2所示。

把測試模版的各個幀號n=1,…,N在一個二維直角坐標系的橫軸上標出,把參考模版的各幀號m=1,…,M在縱軸上標出,通過這些表示幀號的整數坐標畫出的橫縱線即可形成一個網格,網格中的每一個交叉點(n,m)表示測試模版中某一幀與訓練模版中某一幀的交叉點。動態規劃算法可以歸結為尋找一條通過此網格中若干格點的路徑,路徑通過的格點即為測試和參考模版中距離計算的幀號。
整個算法主要歸結為計算測試幀和參考幀間的相似度及所選路徑的矢量距離累加。
識別流程如圖3所示。

3 實驗結果與性能分析及結論
為測試上述識別性能,對其進行了固定文本的說話人識別試驗。試驗中,采用電話信道863語料庫30個說話人共300個錄音文件,文件格式為16 bit線性PCM。為了模擬VoIP中語音壓縮幀,使用G.729聲碼器對原始語音文件進行壓縮。使用每個說話人的一個文件訓練成為模板。測試語音長度為10 s~60 s以5 s為間隔的共11個測試時間標準。這樣,模板庫中有30個模板,測試語音有270個,使用微機配置是:CPU Pentium 2.0 GHz,內存512 MB。
在實驗中,M和N取64,通過各模版間的匹配,確定了判決門限為0.3時,識別效果最佳。
為了對比DTW算法的識別性能,采用在傳統說話人識別中廣泛使用的GMM模型作為對比實驗,其中GMM模型使用與DTW算法相同的編碼流特征。
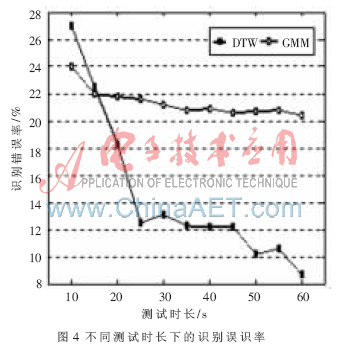
圖4給出基于DTW識別方法與GMM模型(混元數64)識別G.729編碼方案863語料庫的文本相關說話人的誤識率對比圖。橫坐標代表的測試語音的時長,縱坐標代表識別誤識率。由實驗結果可知在文本相關的說話人識別中,基于DTW算法的識別率在絕大多數情況下高于GMM模型,且隨著測試語音的增長,優勢更明顯。
為比較特征提取的時間性能和總的時間性能,實驗條件如下:
(1)選擇的50個說話人的語音只進行特征提取,測試語音長度總和在25 min左右;
(2)對測試語音分別進行解碼識別和編碼流的識別,模板數為10個;
(3)微機配置為:CPU Pentium 2.0 GHz,內存512 MB。
表1為特征提取時間比較結果,表2為說話人識別時間比較結果。

由實驗結果可以看出,在編碼比特流中進行特征提取時間和識別的(上接第121頁)
時間都遠小于解碼重建后的語音特征提取時間和識別時間,滿足實時說話人識別的需要。
在文本相關的說話人識別中,對比使用同樣G.729壓縮碼流特征的GMM模型, DTW方法的識別率和處理效率均高于GMM模型,能夠實時應用于VoIP網絡監管中。
參考文獻
[1] 石如亮.編碼域說話人識別技術研究[D].鄭州:解放軍信息工程大學,2007.
[2] PETRACCA M, SERVETTI A, DEMARTIN J C. Performance analysis of compressed-domain automatic speaker recognition as a function of speech coding technique and bit rate [A]. In: International Conference on Multimedia and Expo (ICME) [C]. Toronto,Canada, 2006:1393-1396.
[3] 石如亮,李弼程,張連海,等. 基于編碼比特流的說話人識別[J].信息工程大學學報,2007,8(3): 323-326.
[4] 王炳錫,屈丹,彭煊.實用語音識別基礎[M].北京:國防工業出版社,2004: 264-286.
[5] 李邵梅,劉力雄,陳鴻昶.實時說話人辨別系統中改進的DTW算法[J].計算機工程,2008,34(4):218-219.
[6] DUNN R B, QUATIERI T F, REYNOLDS D A. et al. Speaker recognition from coded speech in matched and mismatched conditions [A]. In: Proc. Speaker Recognition Workshop’01 [C]. Grete, Greece, 2001:115-120.
[7] AGGARWAL C C, OLSHEFSKI D, SAHA D et al. CSR: Speaker recognition from compressed VoIP packet stream [A]. In: International Conference on Multimedia and Expo (ICME) [C]. Amsterdam, Holand, 2005: 970-973.