
??? 摘 要: 提出了一種基于可編程網(wǎng)絡(luò)處理器IXP2400和GP-CPU的NAT/NAPT" title="NAT/NAPT">NAT/NAPT的實現(xiàn)方案,設(shè)計并實現(xiàn)了基于Intel IXP2400和GP-CPU所組成的具有安全防火墻功能的NAT系統(tǒng)。針對該NAT系統(tǒng)進行了性能分析,它能夠支持六十多萬并發(fā)TCP/UDP的連接容量與全線速為2Gb/s以太網(wǎng)連接速率,有效提高了NAT/NAPT的操作速度,克服了傳統(tǒng)NAT實現(xiàn)方案中的性能瓶頸。
??? 關(guān)鍵詞: 網(wǎng)絡(luò)處理器; IXP2400; NAT; NAPT; 微引擎
?
??? 在現(xiàn)代通信網(wǎng)應(yīng)用中,網(wǎng)絡(luò)地址轉(zhuǎn)換NAT(Network Address Translation)技術(shù)是IETF提出的有效解決IPv4面臨的網(wǎng)絡(luò)地址枯竭問題的方案之一,是為提高網(wǎng)絡(luò)地址利用率、緩解IPv4地址枯竭壓力而采取的一種有效策略。與此同時,為滿足互聯(lián)網(wǎng)絡(luò)對高性能與靈活性的要求,網(wǎng)絡(luò)處理器作為一種可編程的高速處理器應(yīng)運而生,它是新興的下一代網(wǎng)絡(luò)設(shè)備的核心,它綜合了GP-CPU(通用處理器)的完全可編程特性和專用處理器ASIC(Application Specific Integrated Circuit)的高速處理能力的優(yōu)點,有效地兼顧了網(wǎng)絡(luò)設(shè)備的功能靈活性和性能強大性。因此,不但提高了網(wǎng)絡(luò)服務(wù)的處理能力而且還具有高線速處理性能,從而能夠很靈活地適應(yīng)網(wǎng)絡(luò)的各種業(yè)務(wù)性能要求[1]。
對于傳統(tǒng)的基于GP-CPU或ASIC的NAT處理復(fù)雜、負荷過重而造成的性能瓶頸,本文提出了一種基于IXP2400和GP-CPU的NAT系統(tǒng)的實現(xiàn)方案,成功地實現(xiàn)了基于有效的全局地址或用戶配置的飽和度來執(zhí)行NAT模式(包括靜態(tài)NAT與動態(tài)NAT)與NAPT模式(Network Address Port Translation,網(wǎng)絡(luò)地址與端口轉(zhuǎn)換)的動態(tài)切換功能,最高效地實現(xiàn)了網(wǎng)絡(luò)地址復(fù)用,同時大大提高了NAT/NAPT的地址轉(zhuǎn)換能力,克服了傳統(tǒng)的NAT網(wǎng)絡(luò)應(yīng)用方案中因數(shù)據(jù)幀頭處理時間過長所導(dǎo)致的難以保持在NPs上一定的線速問題。
1 網(wǎng)絡(luò)處理器IXP2400和NAT/NAPT的概述
1.1 網(wǎng)絡(luò)處理器IXP2400簡介
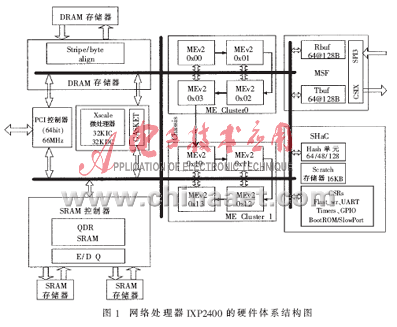
網(wǎng)絡(luò)處理器IXP2400是用來執(zhí)行數(shù)據(jù)處理" title="數(shù)據(jù)處理">數(shù)據(jù)處理和轉(zhuǎn)發(fā)的高速可編程處理器,由一個Xscale Core(智能協(xié)處理單元,即32bit的嵌入式精簡指令集處理器)、8個微引擎" title="微引擎">微引擎Microengines(簡稱MEs),以及標準存儲接口單元和網(wǎng)絡(luò)接口單元等部分組成。IXP2400的硬件體系結(jié)構(gòu)如圖1所示。IXP2400硬件體系結(jié)構(gòu)的詳細描述主要來自于參考文獻[1]、[2]。
?
1.2 NAT/NAPT綜述
NAT具體可分為三種類型:靜態(tài)NAT、動態(tài)NAT和NAPT,分別用來支持IP地址轉(zhuǎn)換以及IP地址與TCP/UDP端口數(shù)據(jù)轉(zhuǎn)換。
NAT映射一個內(nèi)部的IP地址到一個公網(wǎng)IP地址。當(dāng)數(shù)據(jù)包穿過NAT時,不更換它的TCP/UDP端口號。NAT通常使用在一些具備公共IP地址池的NAT上,通過它可以進行地址綁定,即代表一臺內(nèi)部主機。NAPT 則是一種動態(tài)地址轉(zhuǎn)換,它將一個由內(nèi)部IP地址和TCP端口號組成的二元組映射到一個由外部IP地址和TCP端口號組成的二元組,從而允許多個內(nèi)部IP地址共用一個合法外部IP地址[3]。二者都提供了一種機制:實現(xiàn)內(nèi)網(wǎng)的IP地址與公網(wǎng)的IP地址之間的相互轉(zhuǎn)換,并將大量的內(nèi)網(wǎng)IP地址轉(zhuǎn)換為一個或少量的公網(wǎng)合法的IP地址。因此,IP地址轉(zhuǎn)換的應(yīng)用勢在必行。
2 基于IXP2400和GP-CPU的NAT系統(tǒng)的設(shè)計與實現(xiàn)
2.1 系統(tǒng)硬件的設(shè)計與實現(xiàn)
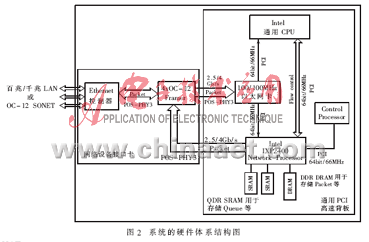
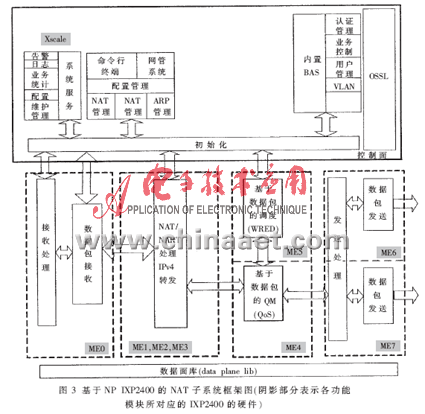
該系統(tǒng)設(shè)計的最終目標是要通過基于IXP2400和GP-CPU來實現(xiàn)具有安全防火墻功能的NAT/NAPT的應(yīng)用方案。該系統(tǒng)的硬件體系結(jié)構(gòu)如圖2所示,其中,基于NP IXP2400的NAT子系統(tǒng)是實現(xiàn)整個NAT系統(tǒng)核心功能的重要組成部分,也是整個NAT系統(tǒng)取得高性能的關(guān)鍵之所在,其結(jié)構(gòu)圖如圖3所示。
?
?
?
該系統(tǒng)的實現(xiàn)平臺主要是由一片集成了時鐘頻率為600MHz的IXP2400的板卡、通用PCI高速背板、一片集成有GP-CPU的主板(即主機系統(tǒng))、運行嵌入式VxWorks實時多任務(wù)操作系統(tǒng)、IDT公司的 PAX.Ware 2500i Media Interface Card、一個100/1000M以太網(wǎng)卡,以及Intel IXA SDK4.2[5]和相關(guān)的構(gòu)建框架(Framework)等部件所組成。
基于IXP2400和GP-CPU的NAT系統(tǒng)能夠提供線速4Gb/s的以太網(wǎng)實現(xiàn)方案[6],并同時支持IPv4的單播轉(zhuǎn)發(fā)。作者通過編輯內(nèi)核相關(guān)的代碼,使GP-CPU具有第二到四層數(shù)據(jù)包過濾功能;同時通過Intel IXA SDK4.2編輯相關(guān)的微代碼,并映射到NP IXP2400中創(chuàng)建一個NAT/NAPT功能模塊,從而實現(xiàn)具有安全防火墻功能的NAT系統(tǒng)的應(yīng)用方案。
2.2 NAT子系統(tǒng)的軟件模塊設(shè)計與實現(xiàn)
基于NP IXP2400的NAT子系統(tǒng)的數(shù)據(jù)流程示意圖如圖4所示。作者把NP IXP2400的8個微引擎分別對應(yīng)地分成具體的功能模塊: Packet RX模塊、NAT/NAPT處理和IPv4轉(zhuǎn)發(fā)功能模塊、Queue Manger模塊、Packet Scheduler模塊以及Packet TX模塊。在設(shè)計方案當(dāng)中,接收、隊列管理及調(diào)度這三個功能模塊各占用一個微引擎,而數(shù)據(jù)包的發(fā)送模塊要占用兩個微引擎來發(fā)送數(shù)據(jù)包,其余三個微引擎用于NAT/NAPT和IPv4轉(zhuǎn)發(fā)的數(shù)據(jù)處理階段。在NAT/NAPT數(shù)據(jù)處理階段中,微引擎的分配使用是通過微引擎內(nèi)部的指令執(zhí)行周期與時延" title="時延">時延周期的數(shù)據(jù)分析來決定的,這一點將在2.3節(jié)中進一步說明。
?
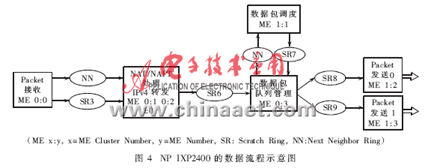
在NP IXP2400中NAT/NAPT的數(shù)據(jù)處理的詳細模塊,如圖5所示。 在Xscale Core(即控制面)與微引擎之間的通信過程中,有兩個Scratch Rings(SR0和SR1)按照優(yōu)先排序的方式處理數(shù)據(jù)并控制數(shù)據(jù)包。作者所設(shè)計的NAT功能模塊既可以通過手動配置運行靜態(tài)NAT模式,同時也可以基于數(shù)據(jù)包運行動態(tài)NAT模式。
?
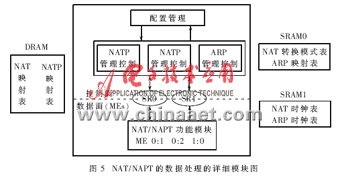
該NAT系統(tǒng)控制著NAT處理模式與NAPT處理模式的轉(zhuǎn)換,這種控制機理的實現(xiàn)是基于有效的全局地址或用戶配置的飽和度,確保內(nèi)部網(wǎng)絡(luò)用戶對外部網(wǎng)絡(luò)不間斷的訪問,并能夠支持更多的網(wǎng)絡(luò)服務(wù)。所以,Xscale Core與 NAT/NAPT MEs(圖5)之間的通信是必不可少的,因為Xscale Core 管理控制著NBT(NAT/NAPT Binding Table,網(wǎng)絡(luò)地址/端口轉(zhuǎn)換映射表)而NAT/NAPT MEs 則是根據(jù)Xscale Core 所管控的 NBT 中所提供的信息來對數(shù)據(jù)包進行處理的。NAT子系統(tǒng)中NAT/NAPT模式的轉(zhuǎn)換是根據(jù)SRAM0中存儲的NAT轉(zhuǎn)換模式表來實現(xiàn)的,如圖5所示。在NAT子系統(tǒng)中運用這種模式轉(zhuǎn)換方案可把模式轉(zhuǎn)換帶來的數(shù)據(jù)傳輸中斷的影響降到了最低限。
2.3? NAT/NAPT功能模塊的微引擎分配
為了保持數(shù)據(jù)處理達到2Gb/s的全線速,NAT/NAPT功能模塊基于每個微引擎在處理數(shù)據(jù)包時,都要求在連續(xù)數(shù)據(jù)包的間隙內(nèi)進行處理。筆者將NAT/NAPT模塊的功能映射到微引擎上來執(zhí)行,是通過估算有效指令執(zhí)行周期與I/O" title="I/O">I/O時延周期來實現(xiàn)的。在以太網(wǎng)接口層,最小的鏈路層數(shù)據(jù)幀的大小為84B(最小的以太網(wǎng)數(shù)據(jù)幀是64B,再加上幀間的數(shù)據(jù)幀頭是20B)。當(dāng)線速為2Gb/s時,如果數(shù)據(jù)包的大小是84B,數(shù)據(jù)包的吞吐量將達到每秒鐘處理2.976M個數(shù)據(jù)包。其中,連續(xù)兩個84B的數(shù)據(jù)包的間隙為336ns。
PacketInterArrivalTime(ns)=PacketSize(Bytes)×8/DataRate(Gb/s)
上式中的幀間間隙可以被設(shè)置成子系統(tǒng)中處理器的時鐘,并由下列公式推導(dǎo)得出。由于NAT子系統(tǒng)是基于IXP2400來實現(xiàn)的,而IXP2400的時鐘頻率為600MHz,因此,該處理器的時鐘應(yīng)為1.67ns。
PacketArrivalTime(ProcessorCycles)=PacketInterArrivalTime(ns)/ProcessorClockTick(ns)
所以,整個數(shù)據(jù)處理流程(如圖4所示)中的任何一個處理進程都必須能夠在特定周期(符合這種周期算法)內(nèi)完成所要求的所有接收到的數(shù)據(jù)包的處理,而且,每個處理進程都應(yīng)該能夠達到每202個周期處理一個新的數(shù)據(jù)包的處理速度,以支持2.0Gb/s的全線速。
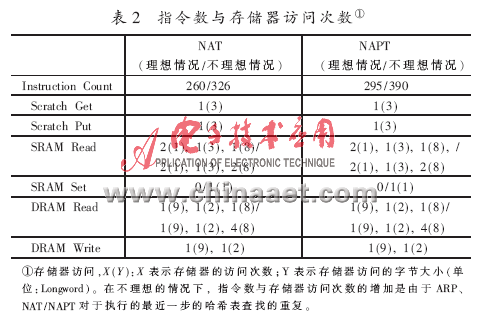
微引擎對數(shù)據(jù)包的處理包括:對內(nèi)存儲器和外存儲器的訪問,例如:Scratch Memory、SRAM、DRAM等。訪問存儲器的時延與相鄰數(shù)據(jù)包之間的間隙是近似的,例如:SRAM存儲器的訪問時延大約是150 Cycles,而DRAM存儲器的訪問時延大約是250~300 Cycles[7]。每個微引擎內(nèi)部有8個硬件線程(Context),采用多線程交換(Multi-Threading)技術(shù)時,由相應(yīng)的硬件結(jié)構(gòu)提供支持,由軟件指令來控制,可以將存儲器的訪問時延隱藏在指令執(zhí)行周期的后面,因此,提供一個I/O時延周期相當(dāng)于數(shù)據(jù)包傳輸速率的8倍,即一個I/O時延周期總計為8×202=1 616 Cycles(即8倍的以太網(wǎng)傳輸模式上的IPv4數(shù)據(jù)包最短到達時間),這樣充分發(fā)揮了微引擎的MIPS性能,提高了系統(tǒng)的并行處理能力。表1展示了不同的NAT/NAPT功能模塊中的微引擎數(shù)量組合(1ME、2MEs、3MEs)所對應(yīng)的有效指令執(zhí)行周期與I/O時延周期的值的變化。如果使用兩個微引擎執(zhí)行NAT/NAPT處理,則上述兩種周期的值要比只有一個微引擎處理時增加兩倍,因為兩個MEs具有16個硬件線程,這樣可以并行處理16路數(shù)據(jù)包。表2展示了估算的指令執(zhí)行次數(shù)和NAT/NAPT功能模塊中存儲器訪問的次數(shù)。在不理想的情況下,根據(jù)每個存儲器訪問類型[7]的時延的數(shù)值計算得出,執(zhí)行NAPT處理時的I/O時延周期大約為2 880 Cycles。 因此,單個微引擎的指令執(zhí)行周期與I/O時延周期要小于兩個微引擎的指令執(zhí)行周期與I/O時延周期。所以,筆者設(shè)計此NAT/NAPT處理和IPv4轉(zhuǎn)發(fā)功能模塊應(yīng)當(dāng)配置三個微引擎并行工作,來支持網(wǎng)絡(luò)所要求的數(shù)據(jù)處理速度。這一分析結(jié)果將在下節(jié)的軟件仿真測試中被證實。

?
3? NAT系統(tǒng)的性能分析
這項仿真測試運用了IXP2400 Developer Workbench專用軟件開發(fā)平臺,通過編譯微代碼來實現(xiàn)數(shù)據(jù)的仿真。在測試當(dāng)中,Workbench編譯器使用的參數(shù)設(shè)置都是默認值。
3.1 最大連接速率/最大會話速率
該性能測試為系統(tǒng)的TCP會話處理性能和峰值速率性能的測試集合。在性能測試之前,ARP的映射條目與NAT/NAPT的轉(zhuǎn)換條目采用動態(tài)配置的形式,關(guān)于最大連接速率與最大會話速率的測試:是通過固定的數(shù)據(jù)幀長度(84B)與60個客戶機和一個服務(wù)器來完成的。這項測試結(jié)果表明了所設(shè)計的NAT系統(tǒng)完全能夠以全線速處理數(shù)據(jù)包。
3.2? 平均轉(zhuǎn)發(fā)速率
在這項仿真測試過程中,當(dāng)所有數(shù)據(jù)包的NMT查找采用一次地址沖突量(N-depth)匹配的方式時,以最小長度64B以太網(wǎng)幀生成于每個網(wǎng)絡(luò)地址,而且NBTs 的查找模式以N-depth匹配方式被靜態(tài)設(shè)置,所有的數(shù)據(jù)包都匯成一股數(shù)據(jù)流,執(zhí)行NAT/NAPT處理的微引擎中的每個線程都會同時去訪問NMT,這樣就會引起DRAM存儲器訪問的沖突。當(dāng)哈希沖突的次數(shù)不斷增加時,DRAM存儲器的負擔(dān)就會增大而且DRAM存儲器的訪問時延也會大大增加,再加上等待數(shù)據(jù)讀入線程的開銷,執(zhí)行NAT/NAPT處理的微引擎中線程將會產(chǎn)生過度的時延。圖中曲線的走勢說明:隨著NBT查找匹配的一次地址沖突量的增加,將會導(dǎo)致平均轉(zhuǎn)發(fā)速率逐漸地降低。
3.3 時延分析
將本NAT系統(tǒng)(包含:子系統(tǒng)中的NAT/NAPT功能模塊)的時延與不具有NAT/NAPT功能僅僅只提供簡單的數(shù)據(jù)包轉(zhuǎn)發(fā)功能的系統(tǒng)的時延進行了對比。在對NAT系統(tǒng)的測試當(dāng)中,ARP的映射條目與NAT/NAPT的轉(zhuǎn)換條目采用靜態(tài)配置的形式。通過對兩個不同的系統(tǒng)的性能仿真測試結(jié)果進行對比,得出以下結(jié)論:①與不具有NAT/NAPT功能的系統(tǒng)的時延相比,具有NAT/NAPT功能的系統(tǒng)的時延要增加6%~30%。②時延的平均增長比率是根據(jù)數(shù)據(jù)包的大小的不同而變化的,也就是說,如果數(shù)據(jù)包的大小在64B~256B范圍內(nèi),其時延的平均增長比率為25%;如果數(shù)據(jù)包的大小在512B~1 518B范圍內(nèi),其時延的平均增長比率為9%。以上測試結(jié)果表明:基于NP的NAT/NAPT功能模塊需要對數(shù)據(jù)包頭進行深度地處理。
NAT技術(shù),對于當(dāng)前的IPv4網(wǎng)絡(luò)中的地址耗盡和路由表的規(guī)模擴大是一個很有效的解決方案,因為網(wǎng)絡(luò)擴大時它需要很少的改變,并能很快地實現(xiàn)地址復(fù)用。作者設(shè)計出一種基于IXP2400和GP-CPU的NAT系統(tǒng)實現(xiàn)方案,成功地實現(xiàn)了地址復(fù)用,并且微引擎的多線程交換技術(shù)與并行處理能力有效地提高了系統(tǒng)的NAT/NAPT模塊數(shù)據(jù)處理的性能,解決了傳統(tǒng)NAT實現(xiàn)方案中的性能瓶頸。
在未來的工作計劃中,作者為了減少系統(tǒng)數(shù)據(jù)處理產(chǎn)生的哈希沖突次數(shù),計劃創(chuàng)建一個新的哈希函數(shù)來減少哈希沖突,還要重新設(shè)計哈希表的數(shù)據(jù)結(jié)構(gòu)來提高存儲器的利用率,最小化存儲器的訪問時延。
參考文獻
[1]?Intel. Intel IXP2400 Network Processor Hardware Reference Manual [M/CD] . USA: Intel Corporation, Oct.2004. [2] ?張宏科,蘇偉,武勇. 網(wǎng)絡(luò)處理器原理與技術(shù)[M].北京:北京郵電大學(xué)出版社,2004,11:18~138.
[3]? STEVENS R W. TCP/IP Illustrated, Volume 2: The Implementation[M].? Beijing: China Machine Press,April.2000: ?63-560.
[4]? Integrated Device Technology.? IDTTM PAX.wareTM 2500i?Evaluation System. 2004.
[5]? Intel. IXP2400 and IXP2800 Network Processor: Programmer’s Reference Manual[M/CD]. USA: Intel Corpora-
?tion, Jan. 2005.
[6] ?Intel. Internet Exchange Architecture Software Building?Blocks Reference Manual [M/CD]. USA: Intel Corporation, ?Feb. 2003.
[7]? LAKSHMANAMURTHY S, LIU K, PUN Y, et al.Network?Processor Performance Analysis Methodology[J]. USA:Intel ??Technology Journal, Aug. 2002,6(3):19-28.